|
Introduction
Data is the cornerstone of businesses from large enterprises to small D2C brands, and huge amounts of it can be collected from websites, mobile apps, chat messages, call centers, business transactions, surveys, and social media platforms, among other channels. All this data represents a gold mine of information that can offer customer insights and lead to new ideas for features or products. However, making sense of the data is easier said than done. The information originates from various channels and in multiple formats. It can be logged erroneously and contain other errors, including missing values. Because it comes from multiple domains, it can include unstructured data like text, images, audio, and video. That is why data preparation is essential. This involves cleaning, curating, transforming, and storing data sets for downstream applications including data analytics and data visualization, as well as predictive intelligence based on machine learning and deep learning models. Data can only provide value once it has been processed from its raw form, and effective data preparation can maximize that value. This article will explain the process of data preparation, especially in terms of data labeling, and will provide a checklist for data engineers to follow. What Is Data Preparation? Data preparation is not an entirely new process in technology companies. Data-driven operations previously focused on statistical analysis of business data from structured tables. The deep learning model has grown over the past decade along with the global penetration of mobile phones, widely available internet access, and cheaper cloud storage facilities. Today an estimated 2.5 quintillion bytes of data are being generated daily. Every user interaction with online companies is recorded, from someone clicking an ad or adding a product to a shopping cart to sharing a photo on a social media app. User-generated data is generally unstructured data: images, text, audio, or video. Such data can be used to train sophisticated deep learning models to predict what users want to type in a text, which branded products are featured in an image, and what kind of customer service will be provided in a phone conversation. For deep learning models to make sense of this data, all data samples need to be labeled. Data labeling tells the machine learning models what knowledge they need to acquire via supervised learning to power smart applications. This makes labeling critical in preparing data sets for training machine learning models. However, data labeling can also represent the chief source of errors, affecting potential improvement in model performance. Machine learning models can only be as accurate as the labeled data, which represents the models’ entire knowledge for the particular use case. For example, the source image data set in a face recognition program requires a label for every face shown in every image. During the labeling process for this data set, every image is reviewed by human subject matter experts, crowdsourced labelers on platforms like Amazon Mechanical Turk, or algorithms. Labeling helps clean and prepare the data set by removing noisy or unusable data. In this case, images that don’t contain any faces, or that show unreadable faces due to poor lighting or angles, should be removed because they won’t be helpful in training a face recognition model. This step also ensures the inclusion of images that are most helpful for the desired use case. Once the data set is reviewed and annotated, it can be used for all subsequent face recognition applications instead of going back to the raw data set. This saves time and effort for data engineers, as well as data scientists who might build novel models using the same data set. Additionally, multiple labels and metadata can be applied to each image during the labeling process so that they’re available for new use cases. A tag that identifies the face as that of a man, woman, or child can be used for different computer vision applications. This can potentially give the data set more flexibility for the future. The labeling can be built upon in subsequent versions of the data set. Once the face recognition model is live in production, new images can be labeled to help the model overcome data drift and augment its performance in the face of changing data distributions. This continued labeling and organizing keeps the models more robust and consistent. Data Preparation Steps There are certain best practices to follow when preparing data sets for deep learning applications. Following is a checklist for data engineers when working with unstructured data: (1) Check data formats Samples in a data set, especially if collected via web scraping or crowdsourcing, may come in multiple data formats. For example, an image could be a JPEG, PNG, or TIFF, while an audio file could be a WAV, MP3, or FLAC. Check whether the data set samples are in different formats, so that you can standardize the format across all samples. (2) Verify data types Certain deep learning applications are based on multimodal data including text, images, audio, video, and structured metadata. For example, a model that predicts what video a user might watch next is trained using multiple data types. It verifies the type of each data sample, then indexes and stores them separately. Note that an individual data type like numbers might also belong to different types like int, float, or string. (3) Verify data dimensions It’s crucial to check the dimensionality of the samples in a data set. For example, a set of images containing faces may be gathered from different cameras, each associated with different default image dimensions. (4) Identify what data needs to be labeled Once you’ve completed the above steps, you can begin data labeling. It may not be feasible in some situations to label each data sample, because manual labeling can be prohibitively expensive and time-consuming. In this case, choose an appropriate number of data samples for labeling. For common machine learning classification use cases, you need to sample data for labeling from each category. (5) Determine what type of labeling to perform The same data sample can be labeled in multiple ways depending on the use case. For instance, an image containing people and cars may be labeled for faces, for segmenting people or cars, or for the vehicle registration plates. (6) Decide who will label the data Data labeling can be performed manually by domain experts, crowdsourced from non-experts, or done programmatically using rule-based or model-based algorithms. Determine which annotators will define what kind of data, depending on their expertise or level of training. If a data set will be labeled using software, then the required configuration parameters, protocols, and performance metrics need to be established so that labeling is consistent. (7) Review data for errors and mistakes Usually, the first round of data labeling contains errors. To improve the data quality and eradicate errors, more experienced annotators should conduct a second or third level of review. Depending on cost, time, and available resources, each data sample can also be independently labeled by multiple annotators; the most commonly provided label can be assigned as the final label. (8) Split the data set into training and testing segments Once a data set is labeled, split it into separate train and test subsets for training and evaluating the model, respectively. Depending on the use case and the amount of available data, the ratio might be 80:20, 90:10, or even 99:1. To obtain more reliable results, k-fold cross-validation is recommended. Multiple training and test sets are sampled randomly, and the final results are averaged across all the different folds. Conclusion Without the protection of systematic data preparation and labeling checks, you may find that poor quality data damages the accuracy and performance of any analysis or models based on that data. If you follow the above guide, you will be able to ensure your data is good quality and labeled accurately. Related Blogs
Comments
Published by Andela Introduction
Data culture refers to an organizational culture of using data to derive insights and make informed business decisions. Companies can build a strong data culture by arming themselves with data and the right set of people, policies, and technologies. A data culture helps companies become more competitive and resourceful by leveraging data. And data-driven companies make better, faster, and more objective business decisions. They promote greater employee engagement and retention, and drive better financial outcomes in terms of revenue, profitability, and operational efficiency. In this article, you'll learn about data culture, what its importance is for modern organizations, and how you can build a strong data culture at your company. Why You Need a Strong Data Culture? Without a solid data culture, organizations will inevitably fail to harness the power of data. As previously stated, data culture refers to a set of beliefs and practices that companies use to cultivate and drive more data-driven decisions. Traditionally, businesses relied on the instinct and gut of a select few leaders to make strategic business decisions. However, with the accumulation and collection of massive volumes of customer and business data, domain expertise and instinct can now be complemented with data-driven insights to make more informed decisions. There are several advantages to building a strong data culture. Some of these include the following:
Every business sector, from product to finance to HR, creates and collects a lot of data from external customers or internal operations. For business heads and decision-makers, it's no longer feasible to stay on top of the ever-increasing volumes of data to better understand and evaluate the current state of their organization. However, with data analysts and scientists embedded across each department, it is possible to tap business insights in real time and respond quickly to changes in business performance. A strong data culture also promotes greater employee engagement and retention. When employees see that decisions are made on the basis of data and not driven just by the highest-paid executives, they feel that they can contribute more insights to influence decision-making. In the long term, this facilitates attracting the best talent in the market who can be incentivized to have a greater say in making key business decisions using data. Moreover, there are also strong financial outcomes associated with building and promoting a data culture. Companies with data-driven cultures benefit from increased revenue, better customer services, and more operational efficiencies leading to improved profitability. How to Build a Strong Data Culture? Building a strong data culture is a long-term endeavor that requires patient support and encouragement from leadership. Companies with strong data-driven cultures have executives who lead by example and establish clear expectations that decisions will be objective and based on data. Data leaders can lead from the front by establishing clear goals and guidelines, investing in technology and training, as well as identifying and rewarding employee behaviors that embody a data-led culture. Beyond leadership setting a tone for the whole organization, let's take a look at a few other components that can help build a strong data culture. 1 Bring Business and Data Science Together One of the first steps in building a data culture is to build a strong data science team consisting of data analysts, data engineers, and data scientists. Having quality in-house data talent is a competitive advantage that reaps multiple benefits, including building a robust culture focused on data. Once a data science team is up and running, it needs to be strategically embedded across various departments of the business. This helps business professionals interact with data professionals more regularly and better understand how the power of data analytics and data science can improve business efficiencies and impact profitability and growth. At the same time, this setting enables data professionals to better understand how the business works and build intuition for developing better data and machine learning–powered tools and products. This creates a positive flywheel where both business and data science teams learn to collaborate better and benefit from their respective skill sets. By bringing business and data science together, everyone in the organization learns to appreciate the value of data and use data-driven insights to improve the quality of their decisions, products, and services. 2 Leverage Data When Creating Goals and Deadlines Driving strategic business goals and metrics by leveraging data is a key aspect of encouraging a data-led culture. When goal-setting exercises are conducted objectively and leaders regularly use data and metrics from previous business quarters or external data about competitors or the overall market, everyone in the organization will start to embrace similar data-driven approaches. Leveraging data for setting new targets also enables every stakeholder in the organization to understand and anticipate their future goals and prioritize their work accordingly. Data-led goal setting is a more democratic and fair-minded process that encourages ownership of respective goals by every employee, as opposed to arbitrary, instinct-led, unilateral decisions made by the leadership. 3 Ensure Everybody Has Access to Data A fundamental step toward attaining a data culture is to democratize access to data across the organization. Data culture is a difficult goal when employees in different parts of a business struggle to obtain data. If you don't give your employees access to your data, they won't be able to utilize it when making decisions. This disenfranchises the data analysts, engineers, and scientists disproportionately, as their day-to-day work is impacted the most. Without a motivated team of data professionals, the downstream benefits of data are unlikely to materialize across various business departments. A strong foundation of data governance and data democratization is a prerequisite to achieving the business goals associated with a robust data culture. 4 Keep Your Data Technology Up-to-Date A critical aspect of building a data culture is employing modern tools and technologies to make it easier for employees to access, analyze, and share data-driven insights. Building a modern data stack with newer components like a metrics layer simplifies data-based operations and analytics for everyone, especially nontechnical business stakeholders. Technology, like data warehouses and metrics layers; data analytics tools, like Tableau or Power BI; and customer relationship management (CRM) tools, like Salesforce, are indispensable for modern businesses. Building the data architecture in a cloud environment like Amazon Web Services further improves access to data and reduces the need for multiple tools with a steep learning curve. The right use of tools for data, collaboration, and customer service goes a long way in fostering the use of technology to drive a strong data-led culture. 5 Provide Training for Employees Having supportive leadership and access to data and technology is of little use if employees are not data literate and able to extract insights from data. This requires further investment in terms of learning and development to empower employees with the necessary skills to explore, understand, and share data-driven insights across the organization. In addition to reducing the skills gap, it also encourages people from nontechnical backgrounds to become more data savvy, collaborate better with data experts, and build more comprehensive data products and solutions to benefit the business. 6 Reward Data-Oriented Decisions and Behavior The primary challenge to becoming a data-driven organization is not technical but cultural. A strong data culture is based on a robust foundation of people, policies, and technology. However, once the initial foundation is in place, data leaders need to maintain and bolster the spirit of data-driven decision-making by incentivizing and rewarding behaviors that embody the culture. At the same time, decisions and behaviors that do not represent a holistic data-led process ought to be called out and questioned until every single employee is on board with the philosophy of using data for every decision. This includes encouraging experimentation to answer key business questions for which data does not exist yet or when the current set of data does not yield compelling evidence. Conclusion In this article, you learned about the importance of a data culture for businesses. It's a formidable task to build a strong data culture and is a top priority for a majority of CEOs. Data-driven companies are in a better position to attract and retain talent, make faster decisions with more conviction, and drive stronger growth and profitability to meet their business goals. According to research by McKinsey & Company, data-driven companies are able to achieve their goals faster and realize at least 20 percent more earnings. Related Blogs 
Web3 is the third generation of the internet based on emerging technologies like blockchains, tokens, DAOs, digital assets, decentralised finance that has the potential to give back control of digital assets back to the users with greater trust and transparency.
Typical web3 applications focus on DAOs, DeFi, Stablecoins, Privacy and digital infrastructure, the creator economy amongst others. The web3 ecosystem represents a promising green space for creators, developers, and various types of tech and non-tech professionals as well. In my talk (video and slides shared above) for Crater's Encrypt 2022 hackathon, I describe how AI can be leveraged to build commercially viable web3 applications for India. I cover a number of relevant AI/ML datasets, models, resources and applications for these domains, recognized by the Ministry of Electronics and Information Technology's National Strategy on Blockchain:
Related Blogs 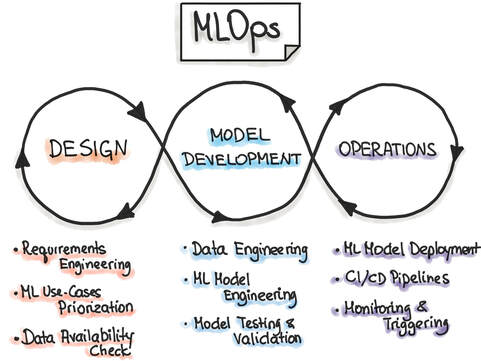 Source: MLOps Org Machine learning operations (MLOps) refer to the emerging field of delivering machine learning models through repeatable and efficient workflows. The machine learning lifecycle is composed of various elements, as shown in the figure below. Similar to the practice of DevOps for managing the software development lifecycle, MLOps enables organizations to smooth the path to successful AI transformation by providing an engineering and technological backbone to underlying machine learning processes.
MLOps is a relatively new field, as the commercial use of AI at scale is itself a fairly new practice. MLOps is modeled on the existing field of DevOps, but in addition to code, it incorporates additional components, such as data, algorithms, and models. It includes various capabilities that allow the modern machine learning team, comprising data scientists, machine learning engineers, and software engineers, to organize the building blocks of machine learning systems and take models to production in an efficient, reliable, and reproducible fashion. MLOps tools MLOps is carried out using a diverse set of tools, each catering to a distinct component of the machine learning pipeline. Each tool under the MLOps umbrella is focused on automation and enabling repeatable workflows at scale. As the field of machine learning has evolved over the last decade, organizations are increasingly looking for tools and technologies that can help extract the maximum return from their investment in AI. In addition to cloud providers, like AWS, Azure, and GCP, there are a plethora of start-ups that focus on accommodating varied MLOps use cases. In this article, I will cover tools for the following MLOps categories:
In the following section, I will list a selection of MLOps tools from the above categories. It is important to note that although a particular tool might be listed under a specific category, the majority of these tools have evolved from their initial use case into a platform for providing multiple MLOps solutions across the entire ML lifecycle. Metadata Management Building machine learning models involves many parameters associated with code, data, metrics, model hyperparameters, A/B testing, and model artifacts, among others. Reproducing the entire ML workflow requires careful storage and management of the above metadata. Featureform Featureform is a virtual feature store. It can integrate with various data platforms, and it enables the management and governance of the data from which features are built. With a unique, feature-first approach, Featureform has built a product called Embeddinghub, which is a vector database for machine learning embeddings. Embeddings are high-dimensional representations of different kinds of data and their interrelationships, such as user or text embeddings, that quantify the semantic similarity between items. MLflow MLflow is an open-source platform for the machine learning lifecycle that covers experimentation and deployment, and it also includes a central model registry. It has four principal components: Tracking, Projects, Models, and Model Registry. In terms of metadata management, the MLflow Tracking API is used for logging parameters, code, metrics, and model artifacts. Versioning For machine learning systems, versioning is a critical feature. As the pipeline consists of various data sets, labels, experiments, models, and hyperparameters, it is necessary to version control each of these parameters for greater accessibility, reproducibility, and collaboration across teams. Pachyderm Pachyderm provides a data layer for the machine learning lifecycle. It offers a suite of services for data versioning that are organized by data repository, commit, branch, file, and provenance. Data provenance captures the unique relationships between the various artifacts, like commits, branches, and repositories. DVC DVC, or Data Version Control, is an open-source version control system for machine learning projects. It includes version control for machine learning data sets, models, and any intermediate files. It also provides code and data provenance to allow for end-to-end tracking of the evolution of each machine learning model, which promotes better reproducibility and usage during the experimentation phase. Experiment Tracking A typical machine learning system may only be deployed after hundreds of experiments. To optimize the model performance, data scientists perform numerous experiments to identify the most appropriate set of data and model parameters for the success criteria. Managing these experiments is paramount for staying on top of the data science modeling efforts of individual practitioners, as well as the entire data science team. Comet Comet is a machine learning platform for managing and optimizing the entire machine learning lifecycle, from experiment tracking to model monitoring. Comet streamlines the experimentation workflow for data scientists and enables clear tracking and visualization of the results of each experiment. It also allows side-by-side comparisons of experiments so users can easily see how model performance is affected. Weights & Biases Weights & Biases is another popular machine learning platform that provides a host of services, including [experiment tracking](https://wandb.ai/site/experiment-tracking). It facilitates tracking and visualization of every experiment, allows rerunning previous model checkpoints, and can monitor CPU and GPU usage in real time. Model Deployment Once a machine learning model is built and tests have found it to be robust and accurate enough to go to production, the model is deployed. This is an extremely important aspect of the machine learning lifecycle, and if not managed well, it can lead to errors and poor performance in production. AI models are increasingly being deployed across a range of platforms, from on-premises servers to the cloud to edge devices. Balancing the trade-offs for each kind of deployment and scaling the service up or down during critical periods are very difficult tasks to achieve manually. A number of platforms provide model deployment capabilities that automate the entire process of taking a model to production. Seldon Seldon is a model deployment software that helps enterprises manage, serve, and scale machine learning models in any language or framework on Kubernetes. It’s focused on expediting the process to take a model from proof of concept to production, and it’s compatible with a variety of cloud providers. Kubeflow Kubeflow is an open-source system for productionizing models on the Kubernetes platform. It simplifies machine learning workflows on Kubernetes and provides greater portability and scalability. It can run on any hardware and infrastructure on which Kubernetes is running, and it is a very popular choice for machine learning engineers when deploying models. Monitoring Once a model is in production, it is essential to monitor its performance and log any errors or issues that may have caused the model to break in production. Monitoring solutions enable setting thresholds as indicators for robust model performance and are critical in solving for known issues, like data drift. These tools can also monitor the model predictions for bias and explainability. Fiddler Fiddler is a machine learning model performance monitoring software. To ensure expected model performance, it monitors data drift, data integrity, and anomalies in the data. Additionally, it provides model explainability solutions that help identify, troubleshoot, and understand underlying problems and causes of poor performance. Evidently Evidently is an open-source machine learning model monitoring solution. It measures model health, data drift, target drift, data integrity, and feature correlations to provide a holistic view of model performance. Conclusion MLOps is a growing field that focuses on organizing and accelerating the entire machine learning lifecycle through best practices, tools, and frameworks borrowed from the DevOps philosophy of software development lifecycle management. With machine learning, the need for tooling is much greater, as machine learning is built on foundational blocks of data and models, as well as code. To bring reliability, maturity, and scale to machine learning processes, a diverse set of MLOps tools are being increasingly used. These tools are developed for optimizing the nuts and bolts of machine learning operations, including metadata management, versioning, model building and experiment tracking, model deployment, and monitoring in production. Over the past decade, the field of AI and machine learning has grown rapidly, with organizations embracing AI and recognizing its critical importance for transforming their business. The field of MLOps is still young, but the creation and adoption of tools will further empower organizations in their journey of AI transformation and value creation. Related Blogs Published by CloudForecast Introduction
Amazon Redshift is a widely used cloud data warehouse that is used by many businesses, like Nasdaq, GE, and Zynga, to process analytical queries and analyze exabytes of data across databases, data lakes, data warehouses, and third-party data sets. There are multiple use cases for Redshift, including enhancing business intelligence capabilities, increasing developer and analyst productivity, and building machine learning models for predictive insights, like demand forecasting. Amazon Redshift can be leveraged by modern data-driven organizations to vastly improve their data warehousing and analytics capabilities. However, the pricing for Redshift services can be challenging to understand, with multiple criteria that define the total cost. In this article, you’ll learn about Amazon Redshift and its pricing structure, with suggestions for how to optimize costs. What Is Amazon Redshift? Essentially, Amazon Redshift provides analytics over multiple databases and offers high scalability in a secure and compliant fashion. Additionally, there is a serverless option called Amazon Redshift Serverless that makes it even easier to rapidly scale analytics setup without requiring a managed data warehouse infrastructure. It helps with data democratization and assists various data stakeholders to extract data insights by simply loading and querying data in the warehouse. Amazon Redshift Pricing In this section, you’ll learn about Amazon Redshift’s capabilities as it pertains to usage and pricing. Free Tier For new enterprise users, the AWS Free Tier provides a free two-month trial of the DC2.Large node. This free service includes 750 hours per month, which is sufficient to run a single DC2.Large node with 160GB of compressed solid-state drives (SSD). On-Demand Pricing When you launch an Amazon Redshift cluster, you select a number of nodes in a specific region as well as their instance type to run your data warehouse. In on-demand pricing, a simple hourly rate applies based on the previous configuration and is billed as long as the cluster is live. The typical hourly rate for a DC2.Large node is $0.25 USD per hour. Redshift Serverless Pricing With Amazon Redshift Serverless, costs accrue only when the data warehouse is active and is measured in units of Redshift Processing Units (RPUs). You’re charged in terms of RPU-hours on a per-second basis. The serverless configuration also includes concurrency scaling and Amazon Redshift Spectrum, and the cost for these services is already included. Managed Storage Pricing Amazon Redshift charges for the data stored in a managed storage at a specific rate per GB-month. Its usage is calculated on an hourly basis as a function of the total amount of data and starts as low as $0.024 USD per GB with the RA3 node. The cost of a managed storage also varies according to the particular AWS region in which the data is stored. For example, consider the cost of a managed storage pricing where 100TB of data is stored with an RA3 node type for thirty days in the US East region, where the cost is $0.024 USD per GB-month. The total usage for thirty days in GB-hours is as follows: 100TB × 1024GB/TB (converting TB to GB) × 30 days × 24 hours/day = 73,728,000 GB-hours Then you can convert GB-hours to GB-months: 73,728,000 GB-hours / (24 × 30) hours per month = 102,400 GB-months Finally, you can calculate the total cost of 102,400 GB-months at $0.024 USD/GB-month in the US East region: 102,400 GB-months × $0.024 USD = $2,457.60 USD Spectrum Pricing With Amazon Redshift Spectrum, users can run SQL queries directly on the data in the S3 buckets. Here, the cost is based on the number of bytes scanned by the Spectrum utility. The pricing of Redshift Spectrum is $5 USD per terabyte of data scanned. Concurrency Scaling Pricing With Concurrency Scaling, Amazon Redshift can be scaled to multiple concurrent users and queries. For every twenty-four hours that your main cluster is live, you accrue a one-hour credit. Any additional usage is charged on a per-second, on-demand rate that depends on the number of types of nodes in the main cluster. Reserved Instance Pricing Reserved instances are designated for stable production workloads and are less expensive than clusters run on an on-demand basis. Significant cost savings can be achieved through long-term usage and commitment to Amazon Redshift in the span of a few years. Pricing for reserved instances can either be paid all up front, partially up front, or monthly over the course of a year with no up-front charges. Amazon Redshift Cost Optimization Considerations Before you begin using Amazon Redshift, you need to be aware of your current costs. AWS Cost ExplorerThe AWS Pricing Calculator provides a configurable tool to estimate the cost of using Amazon Redshift. For instance, the annual cost of one node of the DC2.8xlarge instance in the US East (Ohio) region on an on-demand basis is as follows: 1 instance × $4.80 USD hourly × 730 hours in a month × 12 months = $42,048 USD The cost for the same Amazon Redshift configuration for a reserved instance for a one-year term paid up front is $27,640 USD. AWS Tags Using AWS cost allocation tags can help you decode and manage your AWS costs. Tagsenable AWS resources to be labeled in the form of key-value pairs and can include various types, like technical, business, security, and automation. Once the tags are activated in the Billing and Cost Management console, a cost allocation report can be generated based on the specific resources tagged. Tags can be user-defined or AWS-generated. Amazon Redshift Cost Optimization Optimizing Amazon Redshift costs comes down to effective planning, prudent usage and allocation of resources, and regular monitoring of the usage and associated costs. Optimizing Queries The analytical queries made on the data stored in Amazon Redshift can be optimized to run more efficiently. Queries can be compute-intensive, can be storage-intensive, or can take a long time to execute. There are a number of query tuning techniques that can be used to optimize your queries. Tables with skewed data or missing statistics, and queries with nested loops and long wait times, typically affect query performance and can be improved as illustrated in this AWS developer guide. Here is a commonly used weak query that selects all the columns in a table: SELECT * FROM USERS The previous query can be very inefficient and slow if the table consists of thousands of columns, especially if only a few columns are relevant for the necessary analysis. This query can be optimized by specifying and retrieving the exact column names like the following: SELECT Firstname, Lastname, DOB FROM USERS Cluster Limits and Quotas Usage limits on Amazon Redshift clusters can be programmed using the AWS Command Line Interface (CLI) tool. Limits can be imposed on concurrency scaling in terms of time and spectrum in terms of data scanned. Daily, weekly, or monthly periods can be used. A number of limits and quotas are defined for Redshift resources that can also be applied to constrain the overall costs associated with Redshift. Data Type Amazon Redshift costs can also be managed by storing data in a compressed, partitioned, and columnar data format, like Apache Parquet, since fewer data is scanned. Conclusion Amazon Redshift is a powerful and cost-effective cloud-native data warehouse that provides scalable and performant data analytics and processing capabilities. It also comes with a serverless configuration that allows any data stakeholder to run data queries without the need to provision and manage the data warehouse infrastructure. Amazon Redshift has multiple aspects affecting its pricing, including on-demand or reserved capabilities, serverless, managed storage pricing, Redshift Spectrum pricing, concurrency scaling pricing, and reserved instance pricing. Keeping on top of the various Amazon Redshift costs is not straightforward but can be made easier by AWS cost monitoring tools, like CloudForecast. CloudForecast helps manage AWS costs through daily cost management reports, monthly financial reports, untagged AWS resources discovery, and idle and underutilized resources visibility for cost-saving opportunities. Related blog Strong engineering talent is the bedrock of modern technology companies. Software engineers, in particular, are in high demand given their expertise and skills. At the same time, there is a much greater supply of software companies and startups, all of which are jostling to hire top engineers. Given this market reality, retention of top engineering talent is imperative for a company to grow and innovate in the short as well as the long term.
Retaining employees is critical for numerous reasons. It helps a company retain experience not only in terms of employees’ domain expertise and skills, but also organizational knowledge of products, processes, people, and culture. Strong employee retention rates (>90%) ensure a long-term foundation for success and enhances team morale as well as trust in the company. A stable engineering team is in a better position to both build and ship innovative products and establish a reputation in the market that helps attract top-quality talent. The corporate incentive of maintaining high standards of employee hiring and retention is also related to the costs of employee churn. Turnover costs companies in the US $1 trillion USD a year with an annual turnover rate of more than twenty-six percent. The cost of replacing talent is often as high as two times their annual salary. This is a tremendous expense that can be averted through better company policies and culture. The onus is typically on the human resources (HR) team to develop more employee-friendly practices and promote higher engagement and work–life balance. However, in practice, most HR teams are deferential to the company leadership and that is where the buck stops. Leaders and managers have a fundamental responsibility to retain the employees on their team, as more often than not, employees do not leave the company per se, but the line manager. I will discuss best practices and strategies to improve retention, which ought to be a consistent effort across the entire employee lifecycle--from recruiting to onboarding through regular milestones during an employee’s tenure. Start at the Start More often than not, managers do not invest in onboarding preparation and processes out of laziness and indifference. Good employee retention practice starts at the very beginning, i.e., at the time of hiring. Hiring talent through a structured, transparent, fair, and meritocratic interviewing process that allows the candidate to understand their particular role and responsibilities, the company’s diversity and inclusion practices, and the larger mission of the company sets an important tone for future employees. Hiring the right people who are a good culture fit increases the likelihood of greater engagement and longer tenure at the company. Hiring managers should not hire for the sake of hiring. They should put considerable thought into each new hire and how that hire might fit in on their team. Apart from hiring, managers have other important considerations, including:
In the first few months, the new hires, the hiring team, and company are in a “dating” phase, evaluating each other and gathering evidence on whether to commit to a longer-term relationship. Most new employees make up their mind to stay or leave within the first six months. A third of new hires who quit said they had barely any onboarding or none at all. The importance of a new employee’s first impressions on the joining date, the first week, the first month, and the first quarter cannot be overemphasized. Great onboarding starts before the new hire’s join date, ensuring all necessary preparation is handled, like paperwork. Orientation programs on the join day are essential to introduce the company and expand on its mission, values, and culture beyond what the employee might have learned during the interviews. Minor things like having the team know in advance about a new team member’s join date, and readying the desk, equipment, access, and logins are tell-tale signs of how much thought and effort the hiring team has invested in onboarding. Fellow teammates also make a significant impact, whether they are welcoming and drop in to say “hi” or stop by for a quick chat to get to know the hire better, or take the new employee out for lunch with the whole team. Onboarding should not end on day one but continue in various forms. Some examples include:
A successful onboarding strategy should enable the employee to know their first project, the expectations, associated milestones, and how performance evaluation works. Keep It Up! Onboarding should be followed up with regular check-ins by the manager and HR at the one-month, three-month, and six-month mark. These meetings should be treated as an opportunity for the company to assess the new employee’s comfort level on the team and provide feedback as needed. An onboarding mentor or buddy, if not assigned already, should be provided to help the employee find their feet and learn the informal culture and practices. The manager should set up the employee for success by providing low-hanging projects that are quick to deliver and help the new hire understand the process of building and deploying a new feature using the company’s internal engineering tools and systems. With quick wins, new hires are able to build trust within the organization and gain more confidence to do excellent work. As time goes on, the role of the hiring manager becomes more prominent in coordinating regular 1-on-1 meetings, providing the new hire clear work guidelines, as well as challenging and stimulating projects. Apart from work, an introduction to the organizational setup and culture, as well as social interaction within and beyond the team is also crucial. As the new employee ramps up, it is important to give constructive feedback so that the employee can improve. Where a new employee delivers positive impact in the early days itself, the manager should highlight their work within the team and organization, and motivate the employee to continue to perform well. In addition to core engineering work, employees feel more connected when a company actively invests in their learning and development. Cross-functional training programs that involve employees across different teams foster deeper collaboration and a stronger sense of connection within the various parts of the company. Investment in employees’ upskilling and education via partnership with external learning platforms or vendors also generates a positive culture of instilling curiosity and learning. Learning new skills energizes the employees and provides them opportunities to grow and develop. They can then apply the newly learned knowledge and skills to pertinent business problems. It creates a virtuous culture that yields overall positive outcomes for the employee and employer alike, and positively influences the long-term retention rates. New employees generally feel the need to be positively engaged. A powerful mission statement can sometimes convert naysayers faster and generate a company-wide sense of being part of something impactful. This fosters deeper engagement, loyalty, and trust in the company and helps employees embrace company values, resulting in better employee retention rates. Frequent town hall meetings from the leadership enable a new hire to understand the organization as a coherent whole and their particular role in furthering the company’s mission. Listen to Feedback The diverse organizational efforts to onboard, engage, and enhance new employees’ perception of the company are bound to fail if the organization does not seek and act on any feedback shared by the new hires. Companies ought to create an internal culture of open communication whereby they seek feedback from employees via surveys, meetings, and town halls, and showcase transparent efforts in implementing employees’ suggestions and feedback. Regular 1-on-1 meetings with managers should be treated as an opportunity to gather feedback and offer the employee insights into whether and how the company is taking action on that feedback. However, in spite of organizational efforts to improve employee satisfaction and wellbeing, some attrition is inevitable. Attrition rates of more than ten percent is a cause for concern, however, especially when top-performing employees leave the company. Exit interviews are typically conducted by HR and hiring managers, but in practice these are largely farcical as the employees hardly share their honest opinions and have lost trust that the company can take care of their career interests and development. Companies can implement processes that bring greater transparency around employee decisions related to hiring, promotion, and exit. These processes will also hold HR and managers to greater accountability with respect to employee churn, and incentivize them to increase the retention rates in their teams. In past generations, job stability was a paramount aspiration for employees which meant they typically spent all their working lives at the same company. In today’s world, with a plethora of enterprises and new startups, high-performing talent is in greater demand and it is possible to accelerate one’s career growth by frequently job hopping and switching companies. Nowadays, feedback about company processes, culture, compensation, interviews, and so on, is available on a plethora of public platforms including Glassdoor and LinkedIn. Companies are now more proactive in managing their online reputation and act on feedback from the anonymous reviews on such platforms. Conclusion Employees in the post-Covid remote-working world are prone to greater degrees of stress, mental health issues, and burnout, all of which have adverse impacts on their work–life balance. In such extraordinary times, companies face the unique challenge—and opportunity—to develop and promote better employee welfare practices. At one end of the spectrum, there are companies like Amazon. In 2015, The New York Times famously portrayed the company as a “bruising workplace.” Then, in 2021, The New York Times again reported on Amazon for poor workplace practices and systems, prompting a public acknowledgment from the CEO that Amazon needs to do a better job. On the other end of the spectrum, there are companies like Atlassian or Spotify that have made proactive changes in their organizational culture and are being lauded for new practices to promote employee welfare during the pandemic. Companies that adapt to the changing times and demonstrate that they genuinely care for their employees will enjoy better retention rates, lower costs due to frequent rehiring, and long-term employee trust that conveys the company as a beacon of progressive workplace culture and employment practices. Related Blogs
Data science teams are an integral part of early-stage or growth-stage start-ups as midlevel and enterprise companies. A data science team can include a wide range of roles that take care of the end-to-end machine learning lifecycle from project conceptualization to execution, delivery, and monitoring:
The manager of a data science team in an enterprise organization has multiple responsibilities, including the following:
As the data science manager, it’s critical to have a structured, efficient hiring process, especially in a highly competitive job market where the demand outstrips the supply of data science and machine learning talent. A transparent, thoughtful, and open hiring process sends a strong signal to prospective candidates about the intent and culture of both the data science team and the company, and can make your company a stronger choice when the candidates are selecting an offer. In this blog, you’ll learn about key aspects of the process of hiring a top-class data science team. You’ll dive into the process of recruitment, interviewing, and evaluating candidates to learn how to find the ones who can help your business improve its data science capabilities. Benefits of an Efficient Hiring Process Recent events have accelerated organizations’ focus on digital and AI transformation, resulting in a very tight labor market when you’re looking for data sciencedigital skills, like machinelike data science and machine learning, statistics, and programming. A structured, efficient hiring process enables teams to move faster, make better decisions, and ensure a good experience for the candidates. Even if candidates don’t get an offer, a positive experience interacting with the data science and the recruitment teams makes them more likely to share good feedback on platforms like Glassdoor, which might encourage others to interview at the company. Hiring Data Science Teams A good hiring process is a multistep process, and in this section, you’ll look at every step of the process in detail. Building a Funnel for Talent Depending on the size of the data science team, the hiring manager may have to assume the responsibility of reaching out to candidates and building a pipeline of talent. In larger organizations, managers can work with in-house recruiters or even third-party recruitment agencies to source talent. It’s important for the data science managers to clearly convey the requirements for the recruited candidates, such as the number of candidates desired and the profiles of those candidates. Candidate profiles might include things like previous experience, education or certifications, skill set or tech stack, and experience with specific use cases. Using these details, recruiters can then start their marketing, advertising, and outreach campaigns on platforms, like LinkedIn, Glassdoor, Twitter, HackerRank, and LeetCode. In several cases, recruiters may identify candidates who are a strong fit but who may not be on the job market or are not actively looking for new roles. A database of all such candidates ought to be maintained so that recruiters can proactively reach out to them at a more suitable time and reengage the candidates. Another trusted source of identifying good candidates is through employee referrals. An in-house employee referral program that incentivizes current employees to refer candidates from their network is often an effective way to attract the specific types of talent you’re looking for. The data science leader should also publicize their team’s work through channels, like conferences or workshops, company blogs, podcasts, media, and social media. By investing dedicated time and energy in building up the profile of the data science team, it’s more likely that candidates will reach out to your company seeking data science opportunities. When looking for a diverse set of talent, the search an be difficult as data science is a male dominated field. As a result, traditional recruiting paths will continue to reflect this bias. Reaching out and building relationships with groups such as Women in Data Science, can help broad the pipeline of talent you attract. Defining Roles and Responsibilities Good candidates are more likely to apply for roles that have a clear job description, including a list of potential data science use cases, a list of required skills and tech stack, and a summary of the day-to-day work, as well as insights into the interviewing process and time lines. Crafting specific, accurate job descriptions is a critical—if often overlooked—aspect of attracting candidates. The more information and clarity you provide up front, the more likely it is that candidates have sufficient information to decide if it’s a suitable role for them and if they should go ahead with the application or not. If you’re struggling with creating this, you can start with an existing job description template and then customize it in accordance with the needs of the team and company. It's also critical to not over populate a job description with every possible skill or experience you hope a candidate brings. That will narrow your potential applicant pool. Instead focus on those skills and experiences that are absolutely critical. The right candidate will be able to pick up other skills on the job. It can be useful for the job description to include links to any recent publications, blogs, or interviews by members of the data science team. These links provide additional details about the type of work your team does and also offer candidates a glimpse of other team members. Here are some job description templates for the different roles in a data science team: Interviewing process When compared to software engineering interviews, the interview process for data science roles is still very unstructured, and data science candidates are often uncertain about what the interview process involves. The professional position of data scientist has only existed for a little over a decade, and in that time, the role has evolved and transformed, resulting in even newer, more specialized roles, such as data engineer, machine learning engineer, applied scientist, research scientist, and product data scientist. Because of the diversity of roles that could be considered data science, it’s important for a data science manager to customize the interviewing process depending on the specific profile they’re seeking. Data scientists need to have expertise in multiple domains, and one or more second-round interviews can be tailored around these core skills:
Given how tight the job market is for data science talent, it’s important to not over complicate the process. The more steps in the process, the longer it will take and the higher the likelihood you will lose viable candidates to other offers. So be thoughtful in your approach and evaluate it periodically to align with the market. Types of Data Science Interviews Interviews are often a multistep process and can involve multiple steps of assessments. Screening Interviews To save time, one or more screening rounds can be conducted before inviting candidates for second-round interviews. These screening interviews can take place virtually and involve an assessment of essential skills, like programming and machine learning, along with a deep dive into the candidate’s experience, projects, career trajectory, and motivation to join the company. These screening rounds can be conducted by the data science team itself or outsourced to other companies, like HackerRank, HackerEarth, Triplebyte, or Karat. Onsite Interviews Once candidates have passed the screening interviews, the top candidates will be invited to a second interview, either virtually or in person. The data science manager has to take the lead in terms of coordinating with internal interviewers to confirm the schedule for the series of interviews that will assess the candidate’s skills, as described earlier. On the day of the second-round interviews, the hiring manager needs to help the candidate feel welcome and explain how the day will proceed. Some companies like to invite candidates to lunch with other team members, which breaks the ice by allowing the candidate to interact with potential team members in a social setting. Each interview in the series should start by having the interviewer introduce themself and provide a brief summary of the kind of work they do. Depending on the types of interviews and assessments the candidate has already been through, the rest of the interview could focus on the core skill set to be evaluated or other critical considerations. Wherever possible, interviewers should offer the candidate hints if they get stuck and otherwise try to make them feel comfortable with the process. The last five to ten minutes of each interview should be reserved for the candidate to ask questions to the interviewer. This is a critical component of second-round interviews, as the types of questions a candidate asks offer a great deal of information about how carefully they’ve considered the role. Before the candidate leaves, it’s important for the recruiter and hiring manager to touch base with the candidate again, inquire about their interview experience, and share time lines for the final decision. Technical Assessment It is common for there to be some sort of case study or technical assessment to get a better understanding of a candidate’s approach to problem solving, dealing with ambiguity and practical skills. This provides the company with good information about how the candidate may perform in the role It also is an opportunity to show the candidate what type of data and problems they may work on when working for you. Evaluating candidates After the second-round interviews and technical assessment, the hiring manager needs to coordinate a debrief session. In this meeting, every interviewer shares their views based on their experience with the candidate and offers a recommendation if the candidate should be hired or not. After obtaining the feedback from each member of the interview panel, the hiring manager also shares their opinion. If the candidate unanimously receives a strong hire or a strong no-hire signal, then the hiring manager’s decision is simple. However, there may be candidates who perform well in some interviews but not so well in others, and who elicit mixed feedback from the interview panel. In cases like this, the hiring manager has to make a judgment call on whether that particular candidate should be hired or not. In some cases, an offer may be extended if a candidate didn’t do well in one or more interviews but the panel is confident that the candidate can learn and upskill on the job, and is a good fit for the team and the company. If multiple candidates have interviewed for the same role, then a relative assessment of the different candidates should be considered, and the strongest candidate or candidates, depending on the number of roles to be filled, should be considered. While most of the interviews focus on technical data science skills, it’s also important for interviewers to use their time with the candidate to assess soft skills, like communication, clarity of thought, problem-solving ability, business sense, and leadership values. Many large companies place a very strong emphasis on behavioral interviews, and poor performance in this interview can lead to a rejection, even if the candidate did well on the technical assessments. Job Offer After the debrief session, the data science manager needs to make their final decision and share the outcome, along with a compensation budget, with the recruiter. If there’s no recruiter involved, the manager can move directly to making the candidate an offer. It’s important to move quickly when it comes to making and conveying the decision, especially if candidates are interviewing at multiple companies. Being fast and flexible in the hiring process gives companies an edge that candidates appreciate and take into consideration in their decision-making process. Once the offer and details of compensation have been sent to the candidate, it’s essential to close the offer quickly to prevent candidates from using your offer as leverage at other companies. Including a deadline for the offer can sometimes work to the company’s advantage by incentivizing candidates to make their decision faster. If negotiations stretch and the candidate seems to lose interest in the process, the hiring manager should assess whether the candidate is really motivated to be part of the team. Sometimes, it may move things along if the hiring manager steps in and has another brief call with the candidate to help remove any doubts about the type of work and projects. However, additional pressure on the candidates can often work to your disadvantage and may put off a skilled and motivated candidate in whom the company has already invested a lot of time and money. Conclusion In this article, you’ve looked at an overview of the process of hiring a data science team, including the roles and skills you might be hiring for, the interview process, and how to evaluate and make decisions about candidates. In a highly competitive data science job market, having a robust pipeline of talent, and a fast, fair, and structured hiring process can give companies a competitive edge. Related Blogs Published by Domino Data Lab Reproducibility is a cornerstone of the scientific method and ensures that tests and experiments can be reproduced by different teams using the same method. In the context of data science, reproducibility means that everything needed to recreate the model and its results such as data, tools, libraries, frameworks, programming languages and operating systems, have been captured, so with little effort the identical results are produced regardless of how much time has passed since the original project.
Reproducibility is critical for many aspects of data science including regulatory compliance, auditing, and validation. It also helps data science teams be more productive, collaborate better with nontechnical stakeholders, and promote transparency and trust in machine learning products and services. In this article, you’ll learn about the benefits of reproducible data science and how to ingrain reproducibility in every data science project. You’ll also learn how to cultivate an organizational culture that promotes greater reproducibility, accountability, and scalability. What does it mean to be reproducible? Machine learning systems are complex, incorporating code, data sets, models, hyperparameters, pipelines, third-party packages, model training and development configurations across machines, operating systems, and environments. To put it simply, reproducing a data science experiment is difficult if not impossible if you can’t recreate the exact same conditions used to build the model. To do that, all artifacts have to be captured and versioned in an accessible repository. That way when a model needs to be reproduced, the exact environment, using the exact training data and code, within the exact package combination can be recreated easily. Too often it's an archeological expedition that can take weeks or months (or potentially never) when the artifacts are not captured at the time of creation. While the focus on reproducibility is a phenomenon in data science, it has been a cornerstone of scientific research across all kinds of industries, including clinical and life sciences, healthcare, and finance. If your company is unable to produce consistent experimental results, that can significantly impact your productivity, waste valuable resources, and impair decision-making. Situations Where Reproducibility Matters In data science, reproducibility is especially vital for data scientists to apply the experimental findings to their own work. Regulatory Compliance In highly regulated industries like insurance, finance and life sciences, all aspects of a model have to be documented and captured to provide full transparency, justification and validation on how models are developed and used inside an organization. This includes the type of algorithm being used, why the algorithm has been selected and how the model has been implemented within the business. A big part of complying involves being able to exactly reproduce the results of a model at any time. Without a system for capturing the artifacts, code, data, environment, packages and tools used to build a model this can be a time consuming, difficult task. Model Validation In all industries models should be validated prior to deployment to ensure the results are repeatable, understood and the model will achieve its intended purpose. Too often this is a time intensive process with validation teams having to piece together the environment, tools, data and other artifacts that were used to create the model, which slows down moving a model into production. When an organization is able to reproduce a model instantly, validators can focus on their core function of ensuring the model is robust and accurate. Collaboration Data science innovation happens when teams are able to collaborate and compound knowledge. It doesn’t happen when they have to spend time painstakingly recreating a prior experiment or accidentally duplicate work. When all work is easily reproducible, and easily searched, it's easy to build on prior work to innovate. It also means that as team staffing changes, institutional knowledge doesn’t disappear. Ingraining Reproducibility in Data Science Projects Instilling a culture of reproducibility in data science across an organization requires a long-term strategy, technology investment, and buy-in from data and engineering leadership. In this section, you’ll learn about a few established best practices for conducting and promoting reproducible data science work in your industry. Version Control Version control refers to the process of tracking and managing changes to artifacts, like code, data, labels, models, hyperparameters, experiments, dependencies, documentation, as well as environments for training and inference. The building blocks of version control for data science are more complex than software projects, making reproducibility that much more difficult and challenging. For code, there are multiple platforms, like GitHub, GitLab, and Bitbucket, that can be used to store, update, and track code, like Python scripts, Jupyter Notebooks, and configuration files, in common repositories. However that isn’t sufficient. Datasets need to be captured and versioned as well. So do the environments, tools and packages. This is because code may or may not run the same on a different version of Python or R, for example. Data may have changed even if pulled with the same parameters. Similarly capturing different versions of models and corresponding hyperparameters for each experiment is important to reproduce and replicate the results of a winning model that might be deployed to production. Reproducing end-to-end data science experiments is a complex, technical challenge that can be achieved much more efficiently using platforms like Domino’s Enterprise MLOps platform which eliminates all manual work and ensures reproducibility at scale. Scalable Systems Building accurate and reproducible data science models requires robust and scalable infrastructure for data storage and warehousing, data pipelines, feature stores, model stores, deployment pipelines, and experiment tracking. For machine learning models that serve predictions in real time, the importance of reproducibility is even higher in order to quickly resolve bugs and performance issues. End-to-end machine learning pipelines involve multiple components, and an organizational strategy for reproducible data science work must carefully plan for the tooling and infrastructure to enable it. Engineering reproducible workflows requires sophisticated tooling to encompass code, data, models, dependencies, experiments, pipelines, and runtime environments. For many organizations, it makes sense to buy (vs. build) such scalable workflows focused on reproducible data science. Conclusion Reproducible research is a cornerstone of scientific research. Reproducibility is especially significant for cross-functional disciplines like data science that involve multiple artifacts, like code, data, models, and hyperparameters, as well as a diverse set of practitioners and stakeholders. Reproducing complex experiments and results is, therefore, essential for teams and organizations when making important decisions like which models to deploy, identifying root causes when the models break down, and building trust in data science work. Reproducing data science results requires a complex set of processes and infrastructure that is not easy or necessary for many teams and companies to build in-house. Related Blogs Published by Colabra Introduction
Effective communication skills are pivotal to success in science. From maximizing productivity at work through efficient teamwork and collaboration to preventing the spread of misinformation during global pandemics like Covid19, the importance of strong communication skills cannot be emphasized enough. However, scientists often struggle to communicate their work clearly for various reasons. Firstly, most academic institutes do not prioritize training scientists in essential soft skills like communication. With negligible organizational or departmental training and little to no feedback from professors and peers, scientists fail to fully appreciate the real-world importance and consequences of poor communication skills. The long scientific training period in the academic ivory tower is spent conversing with fellow scientists, with minimal interaction with non-technical professionals and the general public. Thus, the lingua franca among scientists is predominantly interspersed with jargon, leading to poor communication with non-scientists. This article will describe best practices and frameworks for professional scientists and non-scientists in commercial scientific enterprises to communicate effectively. How should scientists speak with non-scientists? IndustryThis section describes how professional scientists in industries like biotech and pharma can communicate better with cross-functional stakeholders from non-technical teams like sales, marketing, legal, business, product, finance, accounting, etc. Cross-functional collaboration In industry, scientists are often embedded in self-contained business or product teams with different roles. Taking a biotech product to market like a new drug, which has a long development cycle, involves extensive collaboration between specialists from multiple domains: research, quality assurance, legal and compliance, project management, risk and safety, vendor and supplier management, sales, marketing, logistics, and distribution, to name a few. Scientists are involved from the beginning of the process. However, scientists are often guilty of focusing solely on R&D without acutely considering how the science and technology underlying the product or business is operationalized by cross-functional teams and delivered to the market. Scientists are often less aware of the practical challenges of taking a drug prototype to the patient, such as long timelines due to multiple steps like risk management, safety reviews, regulatory approvals, coordination with pharmaceutical and logistics companies, and bureaucratic hurdles with governments and international bodies. This is a vital mistake in collaborative industry environments and often leads to poor job experience for scientists and their non-scientist peers and managers. The image below shows several communication challenges at the different stages of the drug development process that hinder successful commercialization. Although the various specialists share a common objective, each domain expert speaks a different “language” influenced by their respective training and fails to translate their opinions and concerns into a common language that all can understand. This comes in the way of optimal decision-making resulting in projects that stall even before demonstrating clinical efficacy. In an industry with a 90% drug development failure rate, poor communication and collaboration can be very expensive, to the tune of USD 1.3 billion per drug. The right culture is crucial to ensure successful outcomes, as advocated by AstraZeneca after a thorough review of their drug development pipeline. A recent real-world example pertains to the development of the AstraZeneca Covid-19 vaccine by multiple teams at the University of Oxford. Although the vaccine was developed within two weeks by February 2020, it was not until 30 December 2020 that the vaccine was finally approved for use in the UK, and it is even to date not authorized for use in the US. In particular, the AstraZeneca vaccine was subject to misinformation, fake news, and fear-mongering, which led to vaccine hesitancy and a lack of public trust. This led Drs. Sarah Gilbert and Catherine Green, co-developers of the vaccine, to author ‘Vaxxers,’ with the primary motivation to allay fears and reassure the general public about its safety and efficacy by explaining the science and process of creating the vaccine. Stakeholder management Another critical aspect of working with cross-functional teams involves managing key stakeholders to ensure a successful outcome for the project. Stakeholders often come from diverse non-scientific backgrounds, making working with them more challenging for scientists. The main challenge in effective stakeholder management is understanding the professional goals, metrics, and KPIs that drive each stakeholder. For instance, a product manager might focus on metrics like cost improvement over time, risk mitigation, or timelines; a finance leader may be focused on revenue; a compliance manager may be focused on metrics that capture safety and legal aspects. Understanding each cross-functional stakeholder’s north star can help scientists navigate the intricacies of stakeholder management. Effective stakeholder management involves numerous aspects: Identifying stakeholders The first step is to identify the stakeholders that are critical to the success of the scientific product and understand their motivations and priorities. Successful stakeholder management starts by mapping your stakeholders across several dimensions, including:
Aligning stakeholders Conflicting priorities among stakeholders are common and need to be resolved delicately. Achieving multi-stakeholder alignment for complex projects requires carefully planned discussions and negotiations to assess the lay of the land with each stakeholder and preempt potential conflicts. Focused group meetings that prioritize key points of disagreement or conflicting priorities can help achieve alignment and avoid conflicts. Engaging stakeholders After getting all the stakeholders aligned, it is useful to build a communication strategy to share project updates regularly. The communication plan must be tailored to each stakeholder. For example, individual contributors might need a high-touch approach, while project coordinators and administrators might just want periodic updates and high-level presentations. During the project's execution phase, continuous engagement and clear communication with the stakeholders are essential to keep everyone on the same page. Stakeholders may be involved in multiple biotech projects in parallel, and your project may not be their sole focus or priority. We have previously written about several modes of communication and project management apart from one-on-one meetings. At a minimum, it is beneficial to maintain a project status board detailing the progress of each milestone, metric, team, and timeline, especially to serve as a single source of truth, especially if some teams are working remotely. Entrepreneurship This section will discuss how aspiring startup founders with a scientific background should communicate and “sell” the company's mission to varied stakeholders from investors, employees, vendors, potential hires, and so on. Scientists with domain expertise and an entrepreneurial mindset are increasingly opting to build deep-tech startups soon after graduating from academia. From Genentech to Moderna and CRISPR Therapeutics to BioNTech, there is no shortage of successful biotech companies founded by scientists. However, building a commercially successful and viable biotech startup requires diverse skills with a much stronger need for excellent communication skills. Scientist founders need to have exceptional communication and sales skills to pitch the company to raise venture capital, write scientific grants, forge business partnerships with other companies, retain customers, attract talented employees with their vision for the company, give media interviews, and shape a mission-oriented organizational culture. Scientist-founders must communicate particularly well to bridge the gap between scientific research and commercialization. How should non-scientists speak with scientists? In this section, we will consider the viewpoint of non-scientists and how they can communicate more effectively with scientists. Non-scientists are typically more focused on product, business, sales, marketing, and related aspects of commercializing scientific research. The stakes for effective communication between scientists and managers are very high. This is best highlighted by NASA’s missions, which involve a diverse set of experts, both scientific and non-scientific, similar to the highly complex and multi-year projects described in the previous section. NASA’s failures on projects like the Columbia mission have been attributed to deficiencies in communication and insular company culture. Namely, management not heeding the scientists' and engineers’ warnings. These communication failures are expertly documented in a post-hoc report by the Columbia Accident Investigation Board – "Over time, a pattern of ineffective communication has resulted, leaving risks improperly defined, problems unreported, and concerns unexpressed," the report said. "The question is, why?" (source) Unfortunately, this state of affairs rings true even today in high-stakes and complex scientific enterprises. Here are some recommended tips that follow from such catastrophic mishaps and failures in workplace communication:
How can non-scientists better engage scientists? Non-scientist stakeholders' work largely focuses on business metrics, product roadmaps, customer research, project management, etc. These are critical focus areas that non-scientists need to update and communicate clearly to their scientist colleagues. In industry, it is common to observe scientist colleagues not actively participating in discussions focused on business topics and switch off until their work is the topic of discussion. It is crucial to engage scientists as they are on the front lines of core product development and in a better position to understand and flag potential roadblocks in manufacturing, commercialization, and logistics based on prior experience. Many product-related issues and bugs that surface later in the development cycle can be caught and addressed if there is more proactive communication between scientific and non-scientific teams. Scientists are generally trained to be conservative, focusing on accuracy and reliability, which can conflict with a manager’s ambitious goals for time-to-market or revenue targets. In these situations, managers should allow scientists to voice their concerns, not be afraid to dive deeper, coordinate with other cross-functional stakeholders, and take a balanced decision integrating every stakeholder’s views. In the long term, cultivating an open and progressive culture that encourages debates and tough discussions reaps enormous benefits whereby no business-critical concern is left unvoiced. A transparent and meritocratic culture promotes greater cooperation and understanding among different teams striving towards the same goals. Conclusion We discussed why scientists often struggle with effective communication with other scientists and non-scientist stakeholders when working in industry or building their own company. We addressed how scientists should approach communication with non-scientist colleagues and how to collaborate with them. We also discussed effective communication strategies from the perspective of non-scientists speaking to scientists. In the long run, having strong communication and soft skills confers greater career durability than simply having scientific and technical skills. Understanding this and upskilling accordingly can empower scientists to transition and perform well in industry. Published by Unbox.ai Introduction
Supervised machine learning models are trained using data and their associated labels. For example, to discriminate between a cat and a dog present in an image, the model is fed images of cats or dogs and a corresponding label of “cat” or “dog” for each image. Assigning a category to each data sample is referred to as data labeling. Data labeling is essential to imparting machines with knowledge of the world that is relevant for the particular machine learning use case. Without labels, models do not have any explicit understanding of the information in a given data set. A popular example that demonstrates the value of data labeling is the ImageNet data set. More than a million images were labeled with hundreds of object categories to create this pioneering data set that heralded the deep-learning era. In this article, you’ll learn more about data labeling and its use cases, processes, and best practices. Why is data labeling important? Labeled data is necessary to build discriminative machine learning models that classify a data sample into one or more categories. Once a machine learning model is trained using data and corresponding labels, it can predict the label of a new unseen data sample. Data labeling is a crucial process as it directly impacts the accuracy of the model. If a significant proportion of the training data set is mislabeled, it will cause the model to make inaccurate predictions. Data labeling of production data is also important to counter data drift. The model can be continuously improved by incorporating the newly labeled samples from the real-world data distribution into the training data set. Poorly labeled data can also introduce bias in the data set, which can cause the models to consistently make inaccurate predictions on a subset of real-world data. Mislabelingcan severely impact the fairness and accuracy of models and warrants additional efforts to detect and eliminate labeling errors. Relabeling helps to address mislabeled samples, improving the data quality and, consequently, the accuracy of the machine learning models. How is data labeling performed? Again, data labeling helps train supervised machine learning models that learn from data and their corresponding labels. For example, the following text, sourced from the Large Movie Review Dataset, can be annotated in a number of ways depending on the use case: I saw this movie in NEW York city. I was waiting for a bus the next morning, so it was 2 or 3 in the morning. It was raining, and did not want to wait at the PORT AUTHORTY. So I went across the street and saw the worst film of my life. It was so bad, that I chose to stay and see the whole movie,I have yet to see anything else that bad since. The year was 69,so call me crazy. I stayed only because I could not belive it.........1. Use case: Sentiment analysis
For the named entity recognition use case, data annotators have to review the entire text and identify and label any mention of places. Typically, data annotation is outsourced to vendors who contract subject matter experts relevant for the specific machine learning use case. The team of annotators are assigned different batches of data to label on a daily basis for the duration of the project, using simple tools like Excel or more sophisticated labeling platforms like Label Studio. Labelers’ performance is evaluated in terms of metrics like overall accuracy and throughput—i.e., the number of samples labeled in a day. If the same set of data samples are assigned to multiple annotators, then the labels given by each annotator can be combined through a majority vote. Inter-annotator agreementhelps to reduce bias and mislabeling errors. For several use cases, data labeling can be extremely painstaking and time-consuming, which may lead to labeling fatigue. To counter this, labels assigned to each annotator undergo one or more rounds of review to catch any systematic errors. Once a batch of data is labeled, reviewed, and validated, it is shared with the data science team, who review select samples for labeling accuracy and verification and then provide feedback to the annotators. This iterative and collaborative process ensures that the final labels are of high quality and accuracy to use for training machine learning models. How is data relabeling performed? The repetitive and manual nature of data labeling is often fraught with errors. This necessitates the need to identify and relabel samples that were erroneously labeled the first time around. Relabeling is an expensive but necessary process as it is imperative to have a training data set of high quality. Unlike labeling, relabeling is usually done on a smaller sample of the entire data set and can be completed much faster if the samples are mislabeled in a unique way or associated with the same annotator. Once a trained model is deployed, its predictions on real-world data can be evaluated. A detailed error-analysis process can sometimes reveal systematic prediction errors. Many times, these characteristic errors may be correlated with a certain type of data sample or feature. In such cases, having another look at similar samples in the training data can help identify mislabeled samples. More often than not, labeling errors on a certain segment of the training data can be captured through such error analysis and corrected with relabeling. Best practices for data labeling Data labeling can be prohibitively expensive and time-consuming for large data sets. As model development is contingent on the availability of good-quality labeled data, poor labeling can affect the timelines and prolong the time to build and deploy machine learning models. A good practice for data scientists is to curate a comprehensive data-annotation framework for each use case before starting the data-labeling process. Clear, structured guidelines with examples and edge cases provide much-needed clarity for annotators to do their job with greater speed and accuracy. In the absence of domain experts within the company, external experts can be sought to discuss and conceptualize guidelines and best practices for labeling specific types of data. As labeling of large data sets by domain experts can be quite expensive, in specific cases, data labeling can be crowdsourced to thousands of users on platforms like Amazon Mechanical Turk. Typically, labeling by crowdsourced users is fast but often noisy and less accurate. Still, crowdsourcing can be a significantly quicker method of collecting the first set of labels before doing one or more rounds of relabeling to eliminate errors. Error analysis is another recommended practice to diagnose model prediction errors and iteratively improve model performance. Error analysis can be done manually by the data scientists or with greater speed and reproducibility using machine learning debugging platforms like Openlayer. Another good practice, in the context of very large data sets for deep learning applications, is to leverage machine learning to obtain a first pass of labels using techniques like the following: Conclusion Machine learning and deep-learning models are typically trained on large data sets. To train such models, a label for each data sample is necessary to teach the model about the information in the data set. Labeling, therefore, is an integral aspect of the machine learning lifecycle and directly influences the quality and performance of models in production. In this article, you’ve seen the importance, process, and best practices for efficient data labeling and relabeling. Mislabeled data samples introduce noise and bias in the data set that adversely impact the performance of the model. Identifying mislabeled examples through error analysis is a proven technique to improve the quality of training data that can be accelerated using machine learning debugging and testing platforms like Openlayer. Related Blogs
Published by Transform Introduction
A metric layer is a centralized repository for key business metric. This “layer” sits between an organization’s data storage and compute layer and downstream tools where metric logic lives—like downstream business intelligence tools. A metric layer is a semantic layer where data teams can centrally define and store business metrics (or key performance indicators) in code. It then becomes a source of truth for metric—which means people who analyze data in downstream tools like Hex, Mode, or Tableau will all be working with the same metric logic in their analyses. The metric layer is a relatively new concept in the modern data stack, mainly because until recently, it was only available to companies with large or sophisticated data teams. Now it is more readily available to all organizations with metric platforms like Transform. In this article, you’ll learn what a metric layer is, how to use your data warehouse as a data source for the metric layer, and how to get value from this central metric repository by consuming metrics in downstream tools. How a Metric Layer fits into a Modern Data StackThe modern data stack is composed of a number of elements organized in the order of how data flows:
One central benefit of a metric layer is that it sits between the data warehouse and downstream analytics tools. People can access metrics in business intelligence (BI) tools like Tableau, Mode, and Hex, bringing metrics consistency across all business analysis. Use cases for the Metric Layer The formulation and implementation of metric layers was pioneered by prominent tech companies like Airbnb, Spotify, Slack, and Uber. Airbnb designed a metric layer called Minerva to serve as a single source of truth (SSOT) metric platform. They did this by standardizing the way metrics are created, calculated, served, and used across the organization. Uber built uMetric, a standardized metric platform that underlies the entire lifecycle of a metric from definition, discovery, planning, calculation, quality, and consumption. These pillars not only enable rapid metric computation for business decisions, but also help create useful features for training ML models and promoting data democratization. A new component in the Modern Data StackWith the emergence of big data, predictive analytics, and data science, most companies have access to enormous amounts of valuable data. Many organizations have evolved their data stack to simplify computation, transformation, and access to key business metrics, which can accelerate data-driven decision-making. However, as Benn Stancil noted in his popular Substack blog, there was no central repository for defining metrics. This causes confusion and misalignment across an organization. "The core problem is that there’s no central repository for defining a metric. Without that, metric formulas are scattered across tools, buried in hidden dashboards, and recreated, rewritten, and reused with no oversight or guidance." —Benn Stancil, The missing piece of the modern data stack Another common issue is “dashboard sprawl” where metric logic is spread across different tools and data artifacts. Since this logic is different for every tool, teams often end up with different numbers for the same metrics and no one knows where to find the “correct” metric to answer their most important business questions. This problem led to the metric layer becoming a new artifact in the modern data stack. With a single shared store of metrics definitions and values, the metric layer ensures consistent and accurate analysis and reporting of metrics. A metric layer not only centralizes key business data but also helps improve the efficiency of data teams by removing the need for repeated analytics. This helps data stakeholders become key advocates and enablers of data-driven decision-making and data democratization across the entire organization. Reutilization of metrics in diverse contexts and external tools One of the benefits of having a single metrics repository is that it can be connected to a variety of tools; for example, CRM’s, BI tools, tools developed in-house, as well as data quality and experimentation tools. A centralized architecture ensures that no matter how a tool’s internal logic is configured, the end result will be based on the same metric logic and consistent across tools and applications. For instance, MetricFlow, the metric layer behind Transform, has an API that enables users to express requests for their Transform metrics directly within SQL expressions. Core metrics like Net Promoter Score (NPS), Monthly Recurring Revenue (MRR), Customer Acquisition Cost (CAC), loan-to-value (LTV), and Annual Recurring Revenue (ARR) capture the health of the business and need to be accurate for reporting and decision-making. With a metric layer, it’s possible to see the lineage of each metric, how it’s built, what the data source is, and how it’s consumed. By unifying metrics extraction and data analytics on these metrics, the metric layer provides the much-needed consistency that is lacking in modern data stacks. Enhancing transparency between technical and non-technical teams with a single interface A single interface for metrics information gives data stakeholders across an organization—in development, sales, marketing, and more—to have the same view and understanding of key metrics to track goals. This consistency allows all of these teams to speak the same language regardless of the tools they use to compute the metrics. This is a tremendous benefit of a metric layer and promotes stronger data democratization and governance across the entire organization. Transform is unique in that it has the addition of a metrics catalog on top of MetricFlow, its open source metric layer. The metrics catalog is a central location where both data teams and non-technical users can interact with, build context, collaborate on, and share key metrics. Tracking changes is easier Because businesses are constantly evolving and creating new metrics or changing the definition of existing metrics, each data stakeholder has to manually keep track of changes in a data warehouse to update their metrics definition and logic. However, with the combination of a metric layer and a metrics catalog, tracking changes metrics owners are alerted anytime the lineage or definition of a metric changes. This enables data stakeholders to make better sense of data, especially when a new metric definition leads to anomalous or unexpected results. Dig into the Metric Layer A metric layer reduces the problem of disparate results when the same metric is computed by different teams using a wide variety of BI tools. And it makes data-driven analytics more precise and promotes faster and more accurate decision-making. If you’re looking for a streamlined and centralized metric layer, MetricFlow is now open source. You can explore the project on Github. Find more information about Transform’s metric layer and its benefits in the product documentation. Related Blogs
Published by StatusHero Introduction
Teams are the building blocks of successful organizations. The success of modern technology companies is driven to a large extent by their engineering and product teams. It is crucial for new engineering and product team leaders to maximize the productivity of their respective teams while ensuring a strong sense of team spirit, motivation, and alignment to the larger mission of the company, as well as fostering an inclusive and open culture that is collaborative, meritocratic, and respectful of each team member. Effective team development and management is therefore critical for engineering and product leaders, and ensuring robust team development at scale remains a big challenge in the face of changing work conditions. Despite the importance of team building and development, not many leaders are trained to succeed and hone their leadership skills. In many cases, individual contributors who progress or transition to the managerial track may not have the aptitude for developing teams nor have the necessary experience or training in this vital aspect of their new role. Although team development is more an art than a science, this topic has received significant interest from the industry as well as academia, leading to structured team development theories and strategies. In this article, you’ll explore a list of curated tips for engineering and product leaders to better manage the development of your teams and accelerate your learning journey on the leadership track. This particular set of tips focuses on building team cohesion, facilitating the five stages of team development, and providing structures for effective teamwork and communication that foster an open and collaborative team culture. Regular Check-Ins One of the fundamental responsibilities of a team leader is to have periodic check-ins with team members, both individually and as a group. These meetings serve as an opportunity to assess each team member’s work performance, their attitude and motivation toward their respective projects, and even their sense of belonging and identity within the team and the organization at large. These regular one-on-one meetings with direct reports also help to bring to light any professional or personal concerns that the manager can then try to address, whether on their own or with the support of colleagues from the human resources department. Group meetings are also essential to allow team members to gather and discuss work issues as a group and voice any concerns that may affect the entire team’s output, productivity, efficiency, or morale. Such group meetings also provide a window for colleagues to learn more about the work and progress made by other members in the team, as well as provide a collaborative atmosphere in which they are encouraged to share their opinions or suggestions. Holding regular retrospectives is a great way to foster discussion and collaboration. As you can see, both individual and group meetings serve as a vital opportunity for team leaders to check the pulse of each member and the team as a whole to assess whether any interventions are necessary to uplift productivity and motivation. Sometimes, these kinds of meetings can be conducted as a retreat or simply at an off-site location to enable team members to bond in a fun environment and encourage more open communication about the team’s development and progress. Structured Work Team members benefit immensely from a high-level structure to guide their work and appropriately allocate their time and resources to the various projects they are involved in. Ideally, all employees should be assigned projects that suit their particular skill set and interests and should be empowered to take ownership for the success of their projects. With individual owners for each team project, the role of the manager is to simply serve each colleague in terms of offering strategic guidance, providing additional resources or bandwidth, and removing any technical or organizational blocks that may otherwise impede their progress. In addition to a clear and structured assignment of work projects, teams also benefit from having a structured work cycle. For instance, engineering teams usually employ an Agile methodology and a regular Scrum cycle to plan their work in sprints and evaluate their progress. Using these proven methodologies helps team members plan their work effectively and encourages feedback from colleagues and the managers to weigh into project planning and management. Over time, if these processes are followed diligently, teams become vastly more organized and productive, leading to more successful projects and deliverables. Five Stages of Team Development According to research by renowned psychologist Bruce Tuckman, there are five distinct stages in a team’s development. These include the following: Forming This is the first stage in a team’s development, in which team leaders introduce individual team members, highlight their respective experience and skills, and facilitate interactions among the team. Knowing each other’s core strengths helps team members better understand who to reach out to for help or collaborate with to execute their projects successfully. Ideally, this stage should be revisited each time a new colleague joins the team to ensure that they feel welcome and to stimulate effective onboarding. Storming Storming is the next stage in a team’s development, which involves team members openly sharing their ideas for current work or new projects in front of the entire team. Team leaders can facilitate this by organizing meetings or events such as hackathons. During this brainstorming stage, it is important that each individual is allowed to freely express their opinions even if they are in conflict with others’. This provides leaders an opportunity to provide high-level clarity and showcase their leadership by effectively resolving any conflicts and motivating team members to disagree and commit for the greater good of the team. Norming During this stage, the team has crossed the initial hurdles and resolved differing opinions, allowing them to begin to hit their stride and work more productively as a unit. With a clear roadmap and a better sense of team success, individual employees begin to celebrate each other’s strengths and weaknesses and collaborate more effectively. Team leaders should congratulate themselves for attaining the norming stage but also be aware of the need to maintain the team’s motivation and momentum toward achieving their goals. Performing By this stage, a team benefits from high levels of cohesion and trust in each other. Teams are more efficient and can self-sustain their progress and velocity with little oversight or push from the team leaders. This enables them to take on more challenging and audacious projects and push the team’s limits in a positive manner. During this stage, team leaders can step in to hone individual team members’ strengths and help them develop and strive for the next step in their careers. Sincere team leaders leverage their coaching and mentorship skills to empower individuals to progress toward their peak efficiency and realize their full potential at work. Adjourning By this stage, teams have completed their projects. This is an excellent opportunity to discuss what went well, what did not go so well, and how to improve and implement new strategies for future team projects. This is a good time to celebrate individual and team successes and to congratulate employees in a public forum, motivating them to strive for even greater success in the future. Team leaders should also take the feedback from the team and leverage it to improve their team building and development methods. Conclusion Developing teams of engineers and product managers is a critical responsibility for the leaders and managers of modern technology companies. When teams operate at their best, the organization as a whole benefits from their productivity and positive momentum. In this article, you’ve learned several tips and strategies on how engineering and product team leaders absorb and implement in their respective teams. These include conducting regular check-ins with individual employees as well as the entire team, providing a structured framework for carrying out their work and executing projects successfully, and following the principles from the five stages of team development. Essentially, leaders should strive to build a team where the whole is greater than the sum of its parts. This not only requires substantial care, attention, and efforts from the leaders but also a high level of empathy and understanding of each individual in the team. Teams with strong, empathetic, servant leaders rise above other teams in an organization, attracting better and more strategic projects and opportunities for collaboration, ultimately resulting in a win for every team member as well as the team leader. Introduction
"Data democratization" has become a buzzword for a reason. Modern organizations rely extensively on data to make informed decisions about their customers, products, strategy, and to assess the health of the business. But even with an abundance of data, if your business can’t access or leverage this data to make decisions, it’s not useful. To that end, data democratization, or the process of making data accessible to everyone, is quintessential to data-driven organizations. Providing data access to everyone also implies that there are few if any roadblocks or gatekeepers who control this access. When stakeholders from different departments—like sales, marketing, operations, and finance—are permitted and incentivized to use this data to better understand and improve their business function, the whole organization benefits. Successful data democratization requires constant effort and discipline. It’s founded on an organization-wide cultural shift that embraces a data-first approach and empowers every stakeholder to comfortably use data and make better data-driven decisions. As Transform co-founder James Mayfield put it, organizations should think about "democratizing insights, not data." In this article, I will provide a detailed overview of data democratization, why organizations should invest in it, and how to actually implement it in practice. Why democratize access to data? Historically, data used to be kept in silos, usually under the purview of the IT or Analytics departments. When any stakeholder from outside these departments required data for their work, they had to go through these data gatekeepers to access the necessary assets. This philosophy has been the norm for decades but is no longer relevant for modern data-driven organizations. Removing these types of bottlenecks is a necessary first step toward data democratization. Guidelines for data democratization can be noted in a data governance framework to improve access and provide high-quality data for downstream analytics. Improving access is just the first step of an ongoing process where every individual employee is encouraged and trained to make use of data. The more people who can make decisions based on data, the more the organization stands to benefit from a variety of perspectives and ideas. Companies have been dedicating huge investments in data infrastructure and tooling in order to build an analytics advantage over their competitors. The dream is to “democratize data” and get employees to change their ways of working and start making decisions informed by data, not gut feelings. By investing in data education and helping analysts influence, then building modern tools to support metrics, we will continue making progress toward that goal of truly democratized data" —James Mayfield, co-founder, Transform While data analytics and business intelligence efforts are traditionally the domain of data experts, organizations can empower non-technical stakeholders to perform basic data operations via in-house training programs, workshops, and self-service tools that can simplify their onboarding and learning process. They can also use software that surfaces data in an easy-to-consume format for business stakeholders. Data democratization has multiple downstream benefits. It leads to greater data literacy, which can facilitate not only greater data-driven decision-making but also potentially lead to creation of new products or services based on insights mined from the data. Therefore, greater democratization, usage, and adoption of a data-driven approach can unlock massive commercial value and new growth levers for businesses. How do you actually democratize data? Implementing data democratization is a hard challenge and an ongoing process. To be successful, it needs support, buy-in, and a lot of patience from the leadership. Apart from conceptualizing and implementing curated data governance frameworks and policies, organizations can leverage tools to enable data democratization at scale. Tools to enable data democratization The Data Catalog A data catalog is a collection of metadata that, combined with data management and search tools, helps data stakeholders find and acquire data for downstream analytics. A data catalog provides a managed and scalable data discovery and metadata management capabilities which are fundamental requirements of attaining higher levels of data democratization in an organization. The Data Mart A data mart is a subset of a data warehouse focused on a specific business vertical or data domain. Data marts enable specific users to access specific data that empowers them to quickly access these datasets without wasting time searching for the same in the data warehouse. For instance, individual departments like sales, marketing, operations, and finance can have their respective data marts for accelerating their domain-specific data-driven decision making. The Metrics Catalog A metrics catalog is a new layer in the modern data stack. It is a centralized store for all of your organizations’ most important metrics (or key performance indicators) and it's uniquely positioned between the data warehouse and downstream tools. As a self-service place for business KPIs, every stakeholder in the organization has access to track their own metrics and share context with others. By capturing core business metrics in this fashion and this location in the modern data stack, a metrics catalog provides immense visibility and transparency into an organization's most critical metrics and metric lineage for all stakeholders in an organization. This new concept of a metrics catalog can have a significant role to play in democratizing data to everyone. As a single source of ground truth for business data, a metrics catalog enables diverse stakeholders to base all key decisions on the same foundation. It also allows for disparate teams to use the same metrics, ask questions, and keep everyone aligned and on track. This greatly enhances the level of data democratization within an organization. Challenges for data democratization Although the benefits of data democratization are pretty evident, there are also numerous challenges. Some challenges are common, like data being kept in silos and unclear data ownership. The informational silos problem is antithetical to data democratization, and can adversely impact an organization's ability to leverage data for improvising its business performance and decision making. Different teams have ownership of different types of data, which contributes to the problem of information silos. When a particular team has exclusive access to specific data assets, they not only hinder other teams from accessing the data but also guard their analysis and insights derived from the same data. This often leads to duplication of efforts across teams, causing a massive waste of organizational time and resources. As each individual team or department hoards its own data and analyses, it contributes to the adoption of the same undemocratic processes across other teams further compounding the challenges in promoting data democratization. With greater access to the organizational data assets, there is also a challenge of data security, privacy, and potential misuse of the data. It increases the number of gaps in the organization which might become vulnerable to adversarial attacks and data breachers. This is why it’s important to have a balance between data security and data access—including having stronger safeguards around who can access and analyze personally-identifiable information and customer data. Looking ahead If implemented well, data democratization can provide an immense competitive edge that will only compound over time as organizations mature in their digital transformation journey. Several tools and data artifacts can aid in better implementation and adoption of best practices and policies that help in democratizing data. A metrics catalog is one relatively new tool that provides a centralized store of business critical information accessible to multiple stakeholders. It captures essential business metrics and provides a simplified interface that is agnostic of the separate analytics, CRM, and BI platforms used by various teams in the organization. Learn more about how a metrics store can promote data democratization and governance at Transform.co. Introduction
Data governance is a fundamental pillar of modern digital businesses. It refers to a framework of processes and guidelines that companies use to ensure all enterprise data assets are managed and utilized appropriately. Even if an organization has large investments in data infrastructure and teams, without a structured data governance framework, organizations will struggle to harness the full value of their data. A strong framework provides a clear set of guidelines for all employees who access and consume data in downstream applications. It also contributes to greater trust in the authenticity and quality of data and allows data stakeholders to focus on core data tasks instead of worrying about whether the data was created, processed, stored accurately, and in compliance with national or domain-related legislations like GDPR, HIPAA, CCPA, and data localization laws. Given recent data breaches, the importance of a structured data governance framework cannot be emphasized enough. In this article, you’ll learn how to ensure data quality through better data governance mechanisms, leading to an increase in data informed decision-making. You’ll also learn how a clear data governance framework contributes to improved data quality and value creation across the entire organization. Why do you need data governance? The digital revolution is founded on data and the idea that data can generate insights that are critical for decision-making and long-term planning. With the emergence of cloud technologies, it’s easier for businesses to see the importance of data and store it in a more accessible, scalable, and secure way. A data governance framework is a set of rules and processes for collecting, storing, and using data. This diagram shows a simplified outline for how to think about building a data governance framework for your organization.However, collecting and storing data is just the tip of the iceberg. Without a clear and robust governance framework, you can’t fully understand the value of your data. High-quality data will help you make the best possible decision for your company. A data governance framework consists of several layers, stakeholders, business goals, and structured processes with a focus on information and project management. This accountability means organizations can build high-quality data products with confidence. This is evident in the case of top technology companies like Google and Amazon that have invested early and massively in data and data-driven technologies. They benefited from investing and enforcing a data governance framework that lowers the organizational threshold, velocity, and efficiency with which businesses can adapt to change. So, why is data governance important? Investing in data governance leads to many benefits including:
Ensure data quality through governance A major outcome of a solid data governance framework, if carried out properly, is improved data quality. When organizations follow these guidelines, it leads to a clearer understanding of their data assets and increases accountability. First, think about your data lineage. Record the source of each data set and the date/time that it is accessed. It’s also critical to understand the teams that are accessing the data including the applications they’re using.This ensures compliance and prevents data breaches. You can test data quality by asking different stakeholder teams to provide the value for a common business metric. More often than not, different teams will have conflicting answers for the same metric. This can be the result of a flaw in your data governance strategy, fuzzy guidelines, or scattered metrics logic across downstream tools. Create policies that ensure data accuracy Maintaining accurate data across the organization is difficult but rewarding. Once a new data asset is created, either internal or external, it needs to be systematically logged and entered into the appropriate databases. Consistently using data governance best practices for completeness, relevance, reliability, and lifecycle can lead to better data quality and accuracy. Develop practices to test data completeness Data completeness refers to the wholeness of the data. Data is complete when there are no missing values, records, or duplicates. Basic automated checks to validate the number of rows and columns, dimensionality, missing and null values, and data format mismatch can help identify missing elements. Adopt technologies to check data relevance Data relevance refers to the utility of data in providing critical insights. It’s important to remember that not all data is useful or relevant to particular business problems, and identifying the right set of input data can help focus subsequent analytics and modeling efforts. Track relevance with data reliability Data reliability is an indicator of how useful and relevant it is over time. It builds upon the concepts of completeness and relevance, and is more likely to be used and reused by teams for their work. This lays the foundation for multiple use cases and business insights. Stay compliant with data depreciation and lifecycleData timeliness and lifecycle management provides clear timelines for the validity and deprecation of data, ensuring that it’s used only when relevant and compliant with privacy laws. This regulates the lifecycle before it is depreciated or deleted permanently. Standardizing metrics as part of your data governance strategy Let’s take a look at how you can standardize your metrics through metrics catalogs and policies and build into a data governance strategy that ensures data quality. Catalog metrics in a metrics storeStandard metrics like annual recurring revenue (ARR), gross merchandise value (GMV), customer acquisition cost (CAC), customer lifetime value (LTV), and net promoter score (NPS) are common. Once you've defined your metrics, these metrics can be stored in a metrics catalog for greater ease of access, use, and re-use across the organization. A metrics catalog has several advantages. It reduces valuable organizational time and effort to reproduce the underlying analysis, and it creates a centralized metrics store that facilitates better understanding and decision-making. As depicted in the figure below, a metrics store is a centralized and governed place for organizations to store key metrics, creating a repository for stakeholders to access key metrics in a repeatable way, regardless of where people access their data. Policies and practices for sign-off Before creating a metric, there needs to be a clear policy on the steps that people use to analyze and validate their business metrics. Data quality policies should not be treated as an administrative exercise but regarded as an important milestone in this stage of data transformation. In addition to assigning an owner for each of your critical metrics, you should also think about executive sponsorship for the organization’s most important, “north-star” metrics. A stamp of approval from the C-suite or an executive sponsor conveys the importance of the data policy framework to the entire organization but can also be used to negotiate and expedite resolutions when conflicts arise. Conclusion In this article, you’ve learned about data quality as an index that can be used for many attributes of data in an organization. A data governance framework creates a set of best practices that improve data accuracy and relevance. A data governance framework also makes it possible to distribute high-quality data to your teams in the most efficient way possible. Building a metrics store is a critical part of this process because metrics are the language that you use to express whether you achieved your organizational goals. A metrics store, like the Transform Metrics Store, centralizes all of this knowledge in one place for easy access and collaboration. To learn more about the metrics catalog and other solutions, visit Transform.co. Introduction
Data drift is a common problem for production machine learning systems. It occurs when the statistical characteristics of the training (source) and test (target) data begin to differ significantly. As illustrated in the image below, the orange curve depicting the original data distribution shifts to the purple curve, representing a change in statistical properties like the mean and variance. Understanding data drift is fundamental to maintaining the predictive power of your production machine learning systems. For instance, a data science team may have started working on a machine learning use case in 2019, using training data from 2018, but by the time the model is ready to go into production, it’s 2020. There could be a huge change in the distribution between the source data from 2018 and the live data coming from 2020. Any time a machine learning model is ready to be shipped, it needs to be rigorously tested on live data. It’s critical that you detect data drift before deploying a model to production. In this article, I’ll illustrate the various types of data drift and how data drift impacts model performance along with several examples. I’ll also address data labeling, one of the popular ways to tackle data drift, and how to perform data labeling efficiently. Why Data Drift Happens? In real-world situations, data drift can occur due to a variety of reasons:
Continuing with the COVID-19 example, a model trained on data prior to the onset of global lockdowns, say from January to February 2020 will yield poor predictions on data in March and April 2020 after the lockdowns started. Thus, the original trained model is no longer relevant or practically useful and needs to be retrained. Even small changes in the data structure or format of the source data can have significant consequences for machine learning models. For instance, a change in the format of a data field, like an IP address or hostname or ID, can often go undetected for a long time without effective root cause analysis. Types of Data Drift There are different types of data drift, but the two principal ones are: Covariate drift refers to data drift associated with a shift in the independent variables. It happens when a few features change while still maintaining the same relationship between the feature and the target variable. Covariate drift primarily occurs due to sample selection bias, which is a systematic bias in the selection of training data that results in a nonuniform and nonrepresentative training dataset. Nonstationary environments, where the training environment differs from the test environment, also cause covariate drift. Concept drift, on the other hand, occurs when the relationship between the independent variables and the target variable changes. Consider a product recommendation machine learning model in the context of e-commerce, where the original model is trained on user activity and transactions from users located in the US. Now imagine that the e-commerce company is going to launch in a new locale or market with the same product catalog as in the US. The original recommendation model will perform poorly when applied to users from the new market with significantly different online shopping behavior, financial literacy, or internet access for e-commerce. In this example, the online shopping behavior of the users is markedly distinct. Even if the same features are used to train the machine learning model, it might underperform significantly. In such cases, concept drift is the root cause of data drift, and the personalization model needs to be reworked and include new features that better capture the new user behavior. Overcoming Drift with Data Labeling To overcome data drift, you need to retrain the model using all available data, including data from before and after drift occurred. New data needs to be labeled accurately before including it in the new training dataset. Data labeling refers to the process of providing meaningful labels to target variables in the context of supervised machine learning where the target could be an image or text or an audio snippet. In the context of data drift, data labeling is crucial to countering data drift, and thereby directly affects the performance of machine learning models in production. Data labeling is integral to supervised machine learning where a model is fed input data along with relevant labels depending on the use case. For example, for a model learning to detect product placement in videos, the model is fed a video with products highlighted in the video. Typically, data labeling is a manual exercise that’s both costly and time-consuming. It’s often outsourced to vendors in developing countries associated with low cost of labor. Annotators need to be trained to use labeling software, understand the machine learning use case and the annotation framework, and deliver highly accurate labels at a high velocity and throughput. In such a scenario, labeling errors can occur, which exacerbates the problem of data drift if data from the new test or target distribution isn’t labeled accurately. In practice, several controversial labeling errors have occurred that cause reputational damage to the company, for instance, when Google Photos labeled two Black people as “gorillas.” Big technology companies like Google and Facebook are grappling with such issues in their automated data labeling algorithms. Labeling errors can be made by human annotators, and also by machine learning models. Once trained, the predictions made by machine learning models on new data are often reused to augment the original training data to further improve the models. In such scenarios, data labeling errors can compound resulting in imperfect models that often yield such bizarre and controversial results. Data labeling helps alleviate data drift by incorporating data from the changed distribution into the original training dataset. If enough new data is labeled, then it is possible to drastically reduce data drift by simply dropping the older data and only using the newly labeled data. Therefore, proper and efficient data labeling is a crucial exercise with significant commercial impact, depending on the nature of the machine learning application. For example, incorrect data labels in a fraud detection use case can result in monetary loss every time the fraud detection machine learning model makes an incorrect prediction. Inaccurate data labels not only impact the performance of the machine learning model but also indirectly contribute to data drift. Any systematic data labeling errors may compound the problem as the model’s predictions on new data are typically leveraged to augment the training dataset. Data labeling can be improvised and performed effectively through the use of intuitive software that enables human annotators to label data with high speed and low cognitive load. For additional improvement in data labeling, you can implement inter-annotator agreement; a particular training example is assigned a label that’s selected by a majority of the annotators. For example, if four out of seven annotators assign “Label1” to a particular data sample and the other three annotators assign it “Label2,” then the data sample would be tagged with “Label1.” Strong operational practices including auditing of randomly selected labels for accuracy can improve the process and provide feedback about systematic labeling errors. You can also use machine learning to aid data labeling with a model trained on a sample of data that’s labeled by humans to generate predictions on new or unlabeled data. These noisy labels can then be leveraged to build better machine learning models by incorporating the data samples associated with high probability and sending the data samples with low probability back to human annotators for more accurate labels. This process can be repeated iteratively to improve the overall performance of the model with minimal human data labeling efforts. Conclusion Data drift can have a negative impact on the performance of machine learning models as data distribution changes. This can cause a machine learning model’s predictive accuracy to go down over time if not countered effectively. Data labeling is one technique to reduce data drift by applying labels to data from the new or changed distribution that the model does not predict well. This helps the machine learning model to incorporate this new knowledge during the training process to improve its performance. There are several tools available today that enable annotators to label data efficiently. For example, Label Studio is an open-source data labeling tool that provides a platform for labeling different data types, including images, text, audio as well as multi-domain data. It’s already used by leading technology companies including Facebook, NVIDIA, Intel, so check it out if you’re looking for a robust, open-source solution for reducing data drift. Published by Neptune.ai Introduction
Only 10% of AI/ML projects have created positive financial impact according to a recent survey of 3,000 executives. Given these odds, it seems that building a profit generating ML project requires a lot of work across the entire organization, from planning to production. In this article, I’ll share best practices for businesses to ensure that their investments in Machine Learning and Artificial Intelligence are actually profitable, and create significant value for the entire organization. Best practices for identifying AI use cases Most AI projects fail at the very first hurdle – poor understanding of the business problems that can be solved with AI. This is the main bottleneck in successful deployment of AI. This problem is compounded by the early stages of organizational intuition for AI, and for how it can be leveraged to solve critical business problems [2]. What does this mean? Well, not every problem can be feasibly solved with AI. To understand if your particular problem can, you need tried and tested practices and approaches. AI use cases AI has transformed industries. It automates routine and manual processes, and provides crucial predictive insights to almost all business functions. Table 1 shows a list of some of the business use cases that have been successfully addressed using AI. Brainstorming appropriate business problems should ideally be done together with business leaders, product managers, and any available subject matter experts. The list of business problems sourced across the organization should then be vetted, and analyzed for potential solutions using AI. Not every business problem should be solved with AI. Oftentimes, a rule-based or engineered solution is good enough. Additionally, a lot of business problems can be mined from customer reviews or feedback, which typically points to broken business processes that need to be fixed. In table 2, you can see a checklist of questions, both technical and commercial, to determine whether a business problem is relevant for AI. KPIs and Metrics As part of the planning process, the appropriate model and business metric for each potential use case should be discussed. Work backwards from the expected outcome, and it’ll be easier to crystallize which particular metric to optimize. To illustrate this, in table 3 I prepared a list of AI use cases and corresponding model and business metrics. For the success of an AI project, it’s ultimately important to ensure the business metric and goals are achieved. Prioritization We have a set of business problems. They’ve been reviewed and documented after careful consideration of the criteria listed in Table 2, and analysis of appropriate business metrics as in Table 3. The candidate list of use cases needs to be prioritized, or ranked, in terms of impact and relevance to the overarching business strategy and goals. From a detailed written document describing comprehensive facets of the business use case and potential AI-based solutions, it’s useful to have objective criteria to quantify all the proposed use cases on the same scale. Here, it’s crucial for product managers and business leaders to have their own intuition about how AI works in practice, or rely on the judgment of a product-focused technical or domain expert. Whilst it’s easy to rank projects on certain success criteria, it’s not so straightforward to rate the risk associated with AI projects. A balanced metric ought to consider and weigh the likelihood and impact of a successful outcome of the AI projects versus the risk of it failing or not generating enough impact. Risks to the project might be related to organizational aspects, domain-specific aspects of the AI problem, or related to external factors beyond the remit of the business. Once a suitable balanced metric is defined, it aligns all stakeholders and leadership, who are then able to form their own subjective views based on the objective scores. A lot of factors need to be considered before a ‘yes’ or ‘no’ decision is made for a particular AI project, as well as the number of AI-relevant projects selected for a defined period. Securing buy-in from the leadership is difficult. Certain final executive decisions might appear subjective or not data-driven, but it’s still absolutely critical to go through the aforementioned planning process to present each AI project in the best light possible, and maximize the likelihood of the AI project being selected for execution. Best practices for planning AI use cases As part of the planning process with cross-functional teams, it’s important for organizations to have a streamlined mechanism for defining the AI product vision or roadmap, the bandwidth, specific roles and responsibilities of individual contributors and managers in each team, as well as the technical aspects (data pipelines, modeling stack, infrastructure for production and maintenance). In this section, I’ll describe the details of specific planning steps essential to build a successful AI product. AI product requirements For each identified use case, it’s necessary to draw the roadmap for how the product will evolve from its baseline version to a more mature product over time. In Table 4, I outline a set of essential questions and criteria to fulfil for creating a comprehensive AI roadmap for each use case. PR-FAQ (Press Release – Frequently Asked Questions) and PRD (Product Requirements Document) are two critical documents that are generally prepared during the initial stages of product ideation and conception. Pioneered by Amazon, these two documents serve as the north star for all concerned teams to align themselves with and build and scale the product accordingly. It’s absolutely essential that all stakeholder teams contribute meaningfully to these documents and share their specific domain expertise to craft a meticulous document for executive review. It’s necessary for all stakeholder team managers to review and contribute to the document, so that any team- or domain-specific intrinsic biases of product development are laid bare and addressed accordingly. Typically, teams should rely on data-driven intuition for product development. In the absence of in-house data, intuition for the AI product can be borrowed from work done by other companies or research in the same field [2, 4]. Data requirementsAs the roadmap is defined and finalized after stakeholder meetings, it’s always beneficial to have an MVP or a basic prototype of the AI product ready to validate initial assumptions and present to the leadership. This exercise also helps to streamline the data and engineering pipelines necessary to acquire, clean and process the data and train the model to obtain the MVP. The MVP should not be a highly sophisticated model. It should be basic enough to successfully transform the input data to a model prediction, and trained on a minimal set of training data. If the MVP is hosted as an API, each of the cross-functional stakeholder teams can explore the product and build intuition for how the AI product might be better developed for the end customer. From a data perspective, the machine learning team can dive deeper into the minimal training data, and do a careful analysis of the data as listed in Table 5. Model requirements After systematic assessment of the data quality, features, statistics, labels and other checks as listed in Table 5, the Machine Learning team can start building the prototype / MVP model. The best approach at the early stages of product development is to act with speed rather than accuracy. The initial (baseline) model should be simple enough to demonstrate that the model works, the data and modeling pipelines are bug-free, and the model metrics indicate that the model performs significantly better than chance. Machine learning use cases and products have become increasingly complex over the years. Whilst linear regression and binary or multi-class classification models were once too common, there are newer classes of models that are faster to train, and generalize better on real-world test data. For the ML scientist or engineer, no two use cases may be built using an identical tech stack of tools and libraries. Depending on the characteristics of the data relevant for the AI use case (see Table 2), the data science team must define the modeling stack specific to each use case (see Table 6 below). Best practices for executing AI use cases After identifying and planning for promising AI use cases, the next step is to actually execute the projects. It might seem that execution is a straightforward process, where the machine learning team gets to weave their magic. But, simply ‘building models’ is not enough for successful deployment. Model building has to be done in a collaborative and iterative fashion:
In the next section, I will discuss the best practices for the operational aspects of executing and deploying AI models successfully and realizing the proposed commercial value. Reviews and feedback Once the AI project has kickstarted, it’s essential for the machine learning team to have both periodic as well as ad-hoc review meetings with stakeholders, including product teams and business leadership. The documents prepared during the planning phase (PR-FAQ and PRD) serve as the context in which any updates or changes should be addressed. The goal of regular meetings is to assess the state of progress vis-a-vis the product roadmap, and address any changes in:
While planning is important, most corporate projects don’t go as initially planned. It’s important to be nimble and agile, respond to any new information (regarding technical, product or business aspects), and re-align towards a common path forward. For example, the 2020 lockdowns severely impacted the economy. In light of such high-impact unexpected events, it’s critical to adapt and change strategy for AI use cases as well. In addition to regular internal feedback, it’s good to keep in touch with the end users of the product throughout the AI lifecycle. In the initial stages (user research, definition of target user personas and their demographics), and especially in product design and interaction with the model predictions. A core group of users from the target segment should be maintained to obtain regular feedback across all stages of product development. Once an MVP is ready, users can be very helpful in providing early feedback that can often bring to light several insights and uncover any biases or shortcomings. When the AI model is ready to be shipped and different model versions are to be evaluated, user feedback can again be very insightful. User insights about the design, ease of use, perceived speed and overall user flow can help the product team to refine the product strategy as needed. Building iterativelyFrom the technical perspective, the model building process is usually an iterative one. After establishing a robust baseline, the team gets insight into how far the model performance is from the established acceptance criteria. In the early stages of model building, the focus should primarily be on accuracy rather than latency. At each stage of model development, a comprehensive analysis of model errors on the validation set can reveal important insights into the model shortcomings, and how to address them. The errors should also be reviewed in conjunction with subject matter experts, to evaluate any errors in data annotation as well as any specific patterns in the errors. If the model is prone to a particular kind of error, it might need additional features. Or it might need to be changed to a model based on a different objective function, or underlying principle, to overcome these errors. This repetitive process helps the machine learning team to consolidate their intuition about the use case, think outside the box, and propose new creative ideas or algorithms to achieve the desired metrics. During the course of model building, machine learning practitioners should systematically document every experiment and the corresponding results. A structured approach is helpful not only for the particular use case, but also helps build organizational knowledge that can be helpful to onboard new hires, or serve as shining examples of successful AI deployment. Deployment and maintenance Once the candidate machine learning model is ready and benchmarked thoroughly on the validation and test sets, errors analyzed, and the acceptance criteria met, the model may be taken to production. There’s a huge difference between the model training and deployment environments. The format in which the model is trained may not be compatible with taking the model to production, and need to be appropriately serialized and converted to the right format. In an environment that simulates the production settings, model accuracy and latency should be validated again on the hold-out dataset. Deployment should be done incrementally by surfacing the model to a small portion of real-world traffic or input to the model, ideally to be tested first by internal or core user groups. Once the deployment pipeline has been rigorously tested and vetted by the MLOps team, more traffic can be directed to the model. In scenarios where one or more candidate models are available, A/B testing of these models should be done systematically, and evaluated for statistically significant differences to determine the winning model. Post-deployment, it’s important to ensure that all the input-output pairs are collected and archived appropriately within the data ecosystem. The launched model should be periodically assessed and the distribution of the real-world data compared with the distribution of the training data to assess for data and model drifts. In such cases, an active learning pipeline that feeds some of the real-world test samples back into the original training dataset helps to alleviate the shortcomings of the deployed model. Finally, once the model production environment and all pipelines are stable, the machine learning and product teams should evaluate the business metrics and KPIs to assess whether the metrics meet the predefined success criteria or not. In case it does, then only can the use case be deemed to be a success and a summary of the overall use case and results should be documented and shared internally with every stakeholder and the business leadership. Wrapping up If machine learning, product and business teams in startups and enterprises adopt a systematic approach and follow the best practices as laid out in this article, then the likelihood of successful AI outcomes can only increase. Adequate upfront preparation is crucial. Without it, teams won’t be able to rectify any errors or respond to changes, nor realize the massive commercial potential that AI can deliver. References
Published by Neptune.ai Introduction
In this article, I have documented the best practices and approaches to build a productive Machine Learning team that creates positive business impact and generates economic value within corporate entities, be it startup or enterprise. If you do Machine Learning, either as an individual contributor or team manager, I’ll help you understand your current team structure and how to improve internal processes, systems and culture. We’ll explore how to build truly disruptive ML teams that drive successful outcomes. Why build an ML team? Artificial Intelligence (AI) is predicted to create global economic value of nearly USD 13 Trillion by 2030 [1]. Most companies across diverse industries and sectors have realized the potential value of AI, and are well on the way to becoming an AI-first entity. From tech companies building cutting-edge AI products like self-driving cars or smart speakers, to traditional enterprises leveraging AI for non-glamorous use cases like fraud detection or customer service automation, the potential of AI to deliver commercial impact is beyond doubt. The adoption of AI in industry is accelerated by a number of trends:
In the following section, I will describe the challenges in building Machine Learning teams for startups and enterprises respectively. Challenges for startups Startups, in the early stages of operations, are typically bootstrapped and have limited budgets to deploy for building machine learning teams. If your startup has a core product or service founded on AI, then it’s imperative to hire machine learning talent early on to build the MVP, and raise funding to hire more talent and scale the product. On the other hand, for startups whose core product or service is focused on other domains like finance, healthcare or education, AI will either be incidental to the core operations, or not essential until product-market fit is achieved. The main challenges of building ML teams in startups are:
In the face of such daunting challenges of machine learning work combined with general organizational challenges at startups [2], it becomes even more important for startups to hire and build the right machine learning team from the very beginning. Challenges for enterprise Unlike startups, big organizations and enterprises don’t suffer from lack of funding or budget to seed a machine learning team. The challenges in an enterprise are unique from one entity to another, but generally arise due to the size of the organization, internal bureaucracy and slower decision making processes – things that tend to benefit startups and help them ship products faster. Although today, it might appear that technology companies are ubiquitous, they’re still a minority compared to the vast number of traditional enterprises focused on diverse sectors like finance, FMCG, retail, healthcare, education and so on. Technology companies have a headstart when it comes to machine learning and AI, and their strong early focus and investment in AI R&D will ensure their dominance compared to their traditional counterparts. However, there are numerous challenges that traditional enterprises face in adopting and onboarding AI across the organization [3], which more often than not result in failed AI projects and reduced trust in the capacity and potential of AI [4]:
Profiles in a Machine Learning team Modern machine learning teams are truly diverse. Yet, at the core, they involve candidates who have strong analytical skills and the ability to understand data from different domains, train and deploy predictive models, and derive business or product insights from the same. SCOPING The first stage of scoping out an AI use case requires AI experts along with business or domain experts. Plenty of successful AI projects start with a deep understanding of the potential business problems that can be solved with AI, and require the combined intuition and understanding of seasoned technical and business experts. In this stage, the usual collaborators involve business leaders, product managers, AI team managers and perhaps one or more senior data scientists with deep, hands-on experience with the underlying data. DATA The second stage is focused on acquiring data, cleaning, processing from the raw form to structured format and storing it in specific on-premise databases or cloud repositories. In this stage, the role of the data engineer is prominent, alongside data scientists. The business and product managers serve a helpful role in providing access to the data, metadata and any preliminary business insights based on rudimentary analytics. MODELING The third stage involves core data science and machine learning modeling using the datasets prepared in the previous stage. In this stage data scientists, applied or research scientists are predominant in training initial models, refining them based on test set performance and feedback from cross-functional stakeholders, developing new algorithms if needed, and finally producing one or more candidate models that meet the required accuracy and latency benchmarks to take the models to production. DEPLOYMENT The final stage of the machine learning lifecycle is focused on deploying trained models to production, where they serve predictions from the inputs received from end users. In this stage, machine learning engineers take the models developed by the data/applied/research scientists and prepare them for production. If the models meet the predefined accuracy and latency benchmarks, the models are good to go live. Otherwise, ML engineers work on optimizing the model size, performance, latency and throughput. Models go through systematic A/B testing procedures before deciding which version(s) of the models are best suited for deployment. Next, I prepared detailed profiles for the different types of experts you may need for your ML team. Data Engineer Skills
Responsibilities
Tech stack
Data Scientist Skills
Responsibilities
Tech stack
Machine Learning Engineer Skills
Responsibilities
Tech stack
Research Scientist Skills
Responsibilities
Tech stack
Product Manager + Business Leader Skills
Responsibilities
Tech stack
Data Science / Machine Learning Manager Skills
Responsibilities
Tech stack
Building productive and impactful Machine Learning teams We explored the typical composition of a Machine Learning team, which includes a variety of different profiles specialized in specific aspects of building machine learning projects. However, the reality on the ground is that having a solid machine learning team is not a guarantee that the team will create and deliver massive business impact. The reality on the ground is that the vast majority of corporate AI projects fail, and a lot of these projects fail despite having a great machine learning team. In this section, I will dive deeper into the cultural, procedural and collaborative aspects of building impactful machine learning teams from first-principles. The success of a machine learning team is founded on several factors related to systems, processes, and culture. When built the wrong way, this will inevitably lead to failed projects and erosion of trust and confidence in the team, as well as machine learning as a business capability and competitive edge. 1. Working on the right AI use cases For a brand new machine learning team to deliver impact in an organization, it’s paramount that the team starts off on the right foot. Early traction is critical to build trust in the organization, evangelize the potential of AI across business verticals, and leverage early successes to deliver riskier or moonshot projects with greater impact. 2. Planning for success – measuring impact As part of the process of selecting and defining the right AI use cases, it’s fundamental to critically assess and evaluate the business impact and return on the investment in the particular machine learning project. The best approach for evaluation is by defining a set of metrics that address several aspects of the project and its potential impact. Technical metrics For classification models:
For regression models:
For deep learning models (depends on the particular application):
Business metrics Business metrics are defined by first-principles, and are often downstream metrics that are impacted by the machine learning models. For measuring outcomes, it’s crucial to a priori identify the relevant business metrics and track the effect of the machine learning models on the same during A/B testing, deployment, and continuously monitor live models. Standard business metrics aim to capture levels of trust, satisfaction, faults, and SLAs, among others. Once a candidate set of machine learning projects is scoped, defined and formulated from conception to production with associated set of metrics, each project needs to be evaluated by leadership teams from the perspective of high-level organizational goals to be achieved in a defined time period. Leaders need to balance the business impact (on the opline or bottomline), budget, team bandwidth, time savings, efficiency savings, and the urgency for delivering projects in the short-term vs. the long term. Executives need to incorporate multiple factors to arrive at a carefully considered decision to give the green signal for one or more machine learning projects. 3. Structured processes – Agile, Sprints Once a project is defined and has the go ahead from the leadership team, it is important to ensure that systems and structured processes are in place to ensure that the machine learning team can work unhindered and execute the project in a timely fashion as per the agreed plan. Key operational infrastructure like data warehouse, database management systems, data ETL pipelines, metadata storage and management platforms, data annotation frameworks and availability of labeled data, access to compute on-prem or in the cloud, licensed as well as open source tools and softwares that streamline the model training process, machine learning experiment, results and metadata management tools, A/B testing platforms, model deployment infrastructure and solutions, continuous model monitoring and dashboards are integral for a smooth data processing, model building, and deployment workflow. However, the existence of such key skeletal infrastructure for machine learning varies from one organization to another depending on how mature the machine learning organization or the company is. Apart from the infrastructure, processes related to planning tasks of the individual contributors of the project using sprints and agile frameworks need to be hardwired and accessible to all stakeholders of the project. While Agile processes have worked well for software projects, machine learning projects are different and may not be that well suited to the same frameworks. Although similarities like iterative model building and refining based on feedback exist, machine learning projects are more sophisticated, as the fundamental blocks include data and models in addition to code. While software engineering best practices like code review and versioning are very well established, the same rigor and structure is not always applied to data and machine learning models. Documentation is another aspect that is even more critical to keep track of multiple hypotheses, experiments, results and all the moving parts associated with machine learning projects. In the absence of well entrenched tools and best practices, most data science work tends to be highly inefficient where data scientists end up spending a lot of time on routine chores that can be automated. It’s imperative that managers try to reduce such barriers to more efficient and productive work, so that the machine learning teams can focus exclusively on their work. 4. Clear communication within and across teams Communication is an essential skill for data scientists. Machine learning is a more intricate discipline and the end results might often be too obscure for generalist and non-technical managers of data science, product or business teams to comprehend easily. However, communication is just the tip of the iceberg, and many more interpersonal skills like persuasion, empathy, collaboration are exercised on a regular basis whilst working in cross-functional teams. Writing emails of results or updates or slide presentations to stakeholders and leadership, live demos, expounding the project for product review documents, writing up the entire project for a blog meant for lay audience or for a journal or conference meant for a technical audience, requires strong writing skills. Typical data scientists may be more proficient in writing code than words, so the organization should invest in corporate training programs for data scientists that include training in written and spoken communication skills. Oral communication skills can’t be underestimated either, and are increasingly important in remote-first organizations. Effective stakeholder management involves building rapport and trust and establishing clear channels of communication, which is much harder to do if a data scientist is not able to speak and communicate clearly in an engaging and delightful manner. Although a lot of workplace productivity apps have created digital channels of reduced in-person communication, the power of live in-person communication with peers, stakeholders and leaders often gets the job done faster. Clear communication destroys information silos, so that each stakeholder is aware, updated and aligned with the progress of various machine learning projects. Regular meetings are important to have checks and balances, in addition to documented progress in tools to ensure that projects are moving in the right direction. 5. Effective collaboration with business Machine learning teams are typically part of the engineering or technology organizations in a company. While this makes natural sense for effective collaboration across colleagues from data, analytics, engineering functions, regular interaction with business teams is a must. Given the fact that most machine learning models are built on historical ‘business’ data that can change in a predictable manner due to new product or feature launches or seasonality patterns, as well as in an unpredictable manner, for instance, during Covid-19 lockdowns, machine learning teams must have a real-time awareness of how the business data is changing on the ground. Not only is it important to adjust the underlying hypotheses in the face of massive changes in customer behavior or new product launches, but also to correct the planned course of action if initial assumptions are violated or the data changes too dramatically for the machine learning models to be relevant or have the same impact as before. Business teams are in the best position to give feedback on early prototypes based on their domain expertise, validate new assumptions or ideas by doing customer research and surveys, and evaluating the impact of deployed machine learning models. For these reasons, the partnership between machine learning and business teams needs to be mutually beneficial and symbiotic. Leaders of machine learning teams need to build close ties with business teams and encourage team members to do the same. 6. Creating a culture of innovation For long-term success of machine learning teams, apart from working on the right use cases and facilitating collaborative work across the organization, it’s imperative to build a culture that embraces and rewards innovation. Here, leadership should lead by example and encourage innovation and R&D across different business verticals. For a machine learning team, it’s critical to make a mark in the ecosystem through patent applications, journal or conference publications, outreach and dissemination via meetups, workshops, seminars by leading experts, collaboration with startups and academic organizations as needed, and so on. Most organizations don’t focus on building such a thriving culture that promotes exchange and cross-fertilization of new ideas and technologies, which can often impact current organizational processes and thinking in a substantial way. Leaders also need to build strong diverse teams and hire new talent, from entry level graduates to experienced engineers and scientists. The inflow of new talent brings in novel ideas that can positively impact the work culture. Otherwise stasis sets in, teams can become narrow-minded, and decline in their capacity to innovate and launch impactful products. Meritocratic executive decisions strongly impact culture, both in terms of promoting talent that demonstrates a consistent track record of exceptional bar-raising work, as well as letting go of non-performing individuals or managers. The appropriate balance and culture in a team is an ongoing process, but it’s important for leaders to ensure that at no point in time, the members of a machine learning team are unmotivated and uninspired by the systems, processes, and culture within the organization. 7. Celebrating and sharing AI success stories Finally, given the low odds of success for AI projects at present, it’s important to make sure that any AI success stories are widely shared within the organization to attract the attention of other business teams who could potentially partner with the machine learning team. Furthermore, given the immense popularity of AI as a discipline, success stories might also attract potential new team members from within the company who feel motivated to upskill in machine learning and become a data scientist. It’s important to recognize the effort of the core contributors to the success of AI projects in a public manner within the company and not behind closed doors. It helps to build morale and confidence and foster a meritocratic culture within the team that will help them in their career development. Additionally, wherever possible, the leadership should take steps to share such AI success stories widely within the broader ecosystem in which the company operates, for instance, via company blogs, social media posts, podcasts or talks at meetups, workshops or conferences. For a machine learning team to continue to deliver strong performance and results, it’s critical to build a portfolio of successful projects starting from simpler ones to gradually more sophisticated ones with an ever increasing scope and commercial impact. The success of a machine learning team acts as a trigger and accelerates the digital and AI transformation of a company. In the highly competitive digital economy, companies that have invested early and invested a lot in AI have emerged as the early winners, for instance, the big tech companies. Thus, impactful machine learning teams act as a lever in the journey towards embracing and onboarding AI and transforming the company into a forward-looking, data-driven, AI-first company. References
Published in BecomingHuman.ai tldr: Poor processes and culture can derail the success of many an exceptional AI team In part 1, I introduced a four-pronged framework for analysing the principal factors underlying the failure of corporate AI projects:
In the second part of the blog series, I will focus on core aspects of organizational processes and culture that companies should inculcate to ensure that their AI teams are successful and deliver significant business impact.  Figure 1. The Facade Culture (source: Dilbert.com) Culture Organizational culture is the foundation on which a company is built and shapes its future outcomes related to commercial impact and success, hiring and retention, as well as the spirit of innovation and creativity. Whilst organizational behaviour and culture have been studied for decades, it needs to be relooked in the context of new-age tech startups and enterprises. The success of such cutting-edge AI-first companies is highly correlated with the scale of innovation through new products and technology, which necessitates an open and progressive work culture. Typically, new startups on the block, especially those building a core AI product or service, are quick to adopt and foster a culture that promotes creativity, rapid experimentation and calculated risk-taking. Being lean and not burdened by any legacy, most tech startups are quick to shape the company culture in the image of the founders’ vision and philosophy (for better or worse). However, the number of tech companies that have become infamous for the lack of an inclusive and meritocratic culture are far too many. There are innumerable examples, from prominent tech startups like Theranos, Uber to big tech companies like Google and Facebook, where an open and progressive culture has at times taken a back seat. However, with the increasing focus on sustainability, diversity and inclusion, and ESG including better corporate governance, it is imperative for tech companies to improve organizational culture and not erode employee, consumer or shareholder trust or face real risks to the business from financial as well as regulatory authorities as recently experienced by BlackRock and Deliveroo. Here is a ready reckoner of some of the ways AI companies tend to lose sight of culture:
 Figure 2. How to scope AI projects (source: DeepLearning.ai) Process There are several processes that are integral for ensuring a successful AI outcome across the entire lifecycle from conception to production. However, from first-principles, the primary process that needs to be streamlined and managed well is identifying the right use cases for AI that have the potential to create significant commercial impact. In this blog, I will focus only on this particular aspect and expound on the other processes in separate blogs. What can go wrong in identifying the right set of AI use cases?
So, having listed a variety of issues that can go wrong in identifying an AI use case, how should one ideally go about scoping AI projects systematically? As per Figure 2, the strategy to scope an AI use case involves 5 steps: from identifying a business problem to brainstorming AI solutions to assessing feasibility and value to determining milestones and finally budgeting for resources. The scoping process starts with a careful dissection of business, not AI problems, that need to be solved for creating commercial value. As discussed above, if not done right, the rest of the AI journey in an organization is bound to fail. Secondly, it is important to brainstorm potential AI solutions across AI, engineering and product teams to shortlist a set of approaches and techniques that are practically feasible instead of going with the latest or most sophisticated AI model or algorithm. Thirdly, AI teams should assess the feasibility of shortlisted methods by creating a quick prototype, validating the approach based on literature survey or discussions with domain experts within the company or partner with external collaborators accordingly. If a particular method does not appear to be feasible, then teams should consider the alternative approaches until they are ruled out. Once the initial efforts have validated the use case, its feasibility and potential approaches, it is critical to define key business metrics, KPIs, acceptance or success criteria. These are not composed of the typical AI model metrics like precision, accuracy of F-1 score, but KPIs need to be defined that are directly correlated with the impact of the AI models on business goals e.g. retention, NPS, customer satisfaction amongst others. The final step involves program management of the entire project from allocating time, bandwidth of individual contributors in the AI as well as partner teams, budget for collecting or labeling data, hiring data scientists or buying software or infrastructure to setup and streamline the entire AI lifecycle. Tldr part 2:
Before you head out to build AI, first ask what are the business problems that are big enough and suitable for an AI-based solution? What business metrics and objectives ought to be targeted? Scope out the problem systematically to ensure the best chance of success. Build on the initial successes of AI and foster a meritocratic and open culture of innovation and cross-functional collaboration to build AI that solves a variety of business use cases. Published in BecomingHuman.ai Tldr: Corporate AI failures can be ascribed to poor Intuition, Process, Systems, People The promise of AI is real. We are at the crossroads of the next industrial revolution where AI is automating industrial processes and technologies that were hitherto considered state-of-the-art. AI is expected to create global commercial value of nearly USD 13 Trillion by 2030 (McKinsey Global Institute). Given the immense commercial value that AI can unlock, it is no surprise that businesses of all kinds and sizes have jumped on the AI bandwagon and are repositioning themselves as ‘AI-first’ or ‘AI-enabled.  Source: Dilbert (https://dilbert.com) However, the groundbreaking progress and transformation that AI has brought across industry belies the stark reality of an increasing number of failed AI projects, products and companies (e.g. IBM Watson, and many more).
How can startups and large enterprises battle these tough odds to drive innovation and digital transformation across the organization? In this blog, I will examine from first principles common themes that typically underlie failed AI projects in corporations, and questions business leaders and teams should address when embarking on AI projects. I have classified these under four broad areas and will tackle each of these themes individually in future blog posts:
Part 1: Intuition (Why) Commercial AI projects often fail due to a lack of organizational understanding of the utility of AI vis-a-vis the business problem(s) to be solved. More often than not, throwing a complex AI-based solution at a problem is not the right approach, where a simpler analytical or rule-based solution is sufficient to have things up and running. It is therefore paramount to decode the business problem first and ask whether an AI approach is the only and best way forward. Unlike software engineering projects, the fundamental unit of AI is not lines of code, but code and data. In an enterprise, data typically belongs to a particular business domain, and is generated by the interaction of customers with specific business products or services. Here, a customer-centric approach is critical to understand the context in which this data is generated so that AI models may be developed to predict or influence user behavior to meet well-defined business objectives with clear success criteria. Wherever possible, the data scientists should themselves use and experiment with their company’s products/services by donning a ‘customer’s hat’ to decode the customer mindset. It’s hard to understand the nuances of training data if you don’t intimately understand the customer ‘persona’ to begin with. Data reflects more than just mere numbers. Making sense of data requires a holistic cross-functional understanding from a business, product, customer as well as technical perspective. Typically, these functional roles are played by different teams within a company, necessitating a strong collaborative effort to demystify the business problem, question the existing solutions and come up with new hypotheses, test and prove or disprove these hypotheses quickly via iterative experiments to hone in on a feasible solution and strategy. Here, the importance of domain knowledge or subject matter expertise cannot be stressed enough. It takes years to gain deep domain expertise which enables practitioners to develop better intuition for the business problem and the underlying data to propose feasible solutions or strategies. As data scientists typically lack expertise in business domains, it is imperative they complement their algorithmic data science skills with expert knowledge from those who work closely with the customer and understand the business problem intimately. Tldr (Part 1/4): Ask why is AI needed for your business problem? Is it the only way to solve the problem? And if yes, build and test hypotheses by leveraging the collective organizational knowledge and intuition across cross-functional teams that specialize in data science, business, product, operations. |
Archives
March 2024
Categories
All
Copyright © 2024, Sundeep Teki
All rights reserved. No part of these articles may be reproduced, distributed, or transmitted in any form or by any means, including electronic or mechanical methods, without the prior written permission of the author. Disclaimer
This is a personal blog. Any views or opinions represented in this blog are personal and belong solely to the blog owner and do not represent those of people, institutions or organizations that the owner may or may not be associated with in professional or personal capacity, unless explicitly stated. |
||


 RSS Feed
RSS Feed