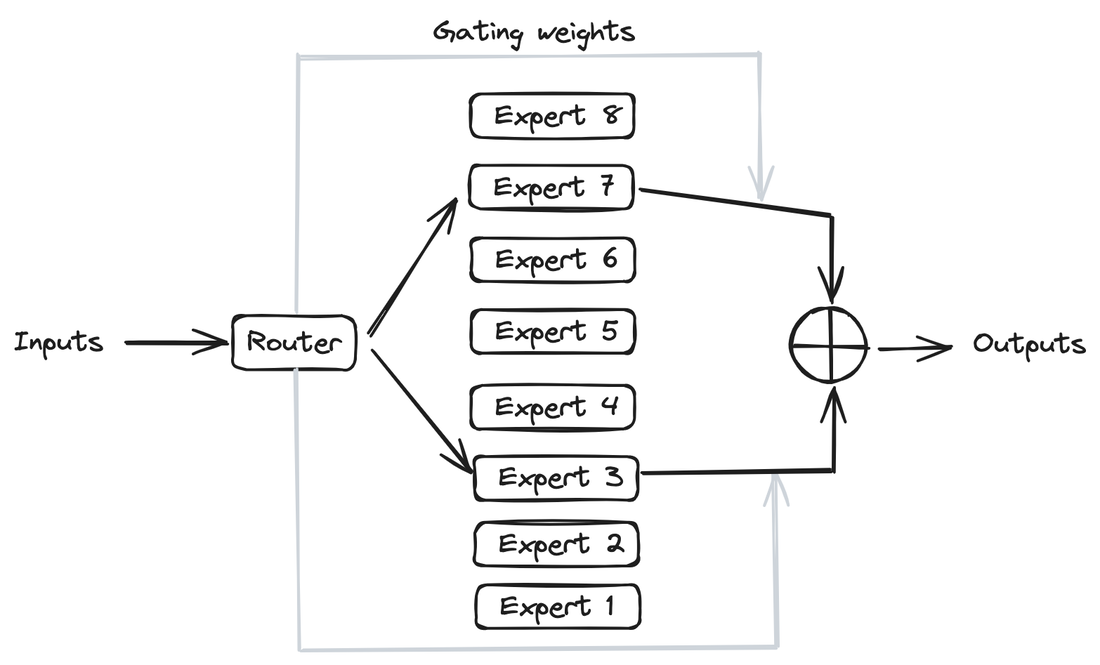
 Figure 1 - Mixture of Experts layer. 1. Introduction Mistral is a pioneering French AI startup that launched their own foundational large language model, called Mistral 7B in September 2023. As of the date of launch, it was the best 7 billion parameter language model, outperforming even larger language models like Llama 2 of size 13 billion parameters across multiple benchmarks. In addition to its performance, Mistral 7B is also popular as the model is open-sourced under the Apache 2.0 license with the model weights available for download. Mixtral 8x7B (hereafter, referred to as “Mixtral”) is the latest model released by Mistral in January 2024 and represents a significant extension of their prior work on Mistral 7B. It is a 7B Sparse Mixture of Experts (SMoE) language model with stronger capabilities than Mistral 7B. It uses 13B active parameters during inference out of a total of 47B parameters, and supports multiple languages, code, and 32k context window. In this blog, you will learn about the details of the Mixtral language model architecture, its performance on various standard benchmarks vis-a-vis state-of-the-art large language models like Llama 1 and 2 and GPT3.5, as well as potential use cases and applications. 2. Mixtral Mixtral is a mixture-of-experts network, similar to [GPT4]. While GPT4 is said to constitute 8 expert models of 222B parameters each, Mixtral is a mixture of 8 experts of 7B parameters each. Thus, Mixtral only requires a subset of the total parameters during decoding, thus allowing faster inference speed at low batch sizes and higher throughput at large batch sizes. 2.1 Sparse Mixture of Experts Figure 1 illustrates the Mixture of Experts (MoE) layer. Mixtral has 8 experts, and each input token is routed to two experts with different sets of weights. The final output is a weighted sum of the outputs of the expert networks, where the weights are determined by the output of the gating network. The number of experts (n) and the top K experts are hyperparameters that are set to 8 and 2 respectively. The number of experts, n determines the total or sparse parameter count while K determines the number of active parameters used for processing each input token. The MoE layer is applied independently per input token in lieu of the feed-forward sub-block of the original Transformer architecture. Each MoE layer can be run independently on a single GPU using a model parallelism distributed training strategy. 2.2 Mistral 7B Mixtral’s core architecture is similar to Mistral 7B, and therefore, a review of its architecture is relevant for a more comprehensive understanding of Mixtral. Mistral 7B is based on the Transformer architecture. In comparison to Llama, it has a few novel features that contribute to it surpassing Llama 2 (13B) on various benchmarks. 2.2.1 Grouped-Query Attention Grouped-Query Attention (GQA) is an extension of multi-query attention, which uses multiple query heads but single key and value heads. Popular language models like PaLM employ multi-query attention. GQA represents an interpolation between multi-head and multi-query attention with single key and value heads per subgroup of query heads. As shown in figure 2, GQA divides query heads into G groups, each of which shares a single key and query head. It is different to multi-query attention which shares single key and value heads across all query heads. GQA is an important feature as it significantly accelerates the speed of inference and also reduces the memory requirements during decoding. This enables the models to scale to higher batch sizes and higher throughput, which is a critical requirement for real-time AI applications. 2.2.2 Sliding Window Attention Sliding window attention (SQA), introduced in the Longformer architecture exploits the stacked layers of a Transformer to attend to information beyond the typical window size. SWA is designed to attend to a much longer sequence of tokens than vanilla attention, and also offers significant reductions in computational cost. The combination of GQA and SWA collectively enhance the performance of Mistral 7B and therefore Mixtral relative to other language models like the Llama series. 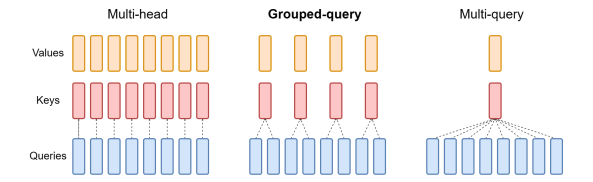 Figure 2. A comparison of the configuration of key, value and query heads for GQA vs. multi-head and multi-query attention. 3. Performance 3.1 Standard benchmarks The authors of Mixtral benchmarked the performance of the model on a range of standard benchmarks and evaluated the accuracy of Mixtral versus leading language models like Llama 1, Llama 2, and GPT3.5 as shown in figure 3, table 1, and table 2. In summary, Mixtral is better than much larger language models with up to 70B parameters like Llama 2 70B while only using 13B (~18.5%) of the active parameters during inference. Mixtral’s performance is especially superior in tasks focused on mathematics, code generation, as well as multilingual comprehension. 3.2 Multilingual understanding Table 3 shows the performance of Mixtral versus Llama models on multilingual benchmarks. As Mixtral was pretrained with a significantly higher proportion of multilingual data, it is able to outperform Llama 2 70B on multilingual tasks in French, German, Spanish, and Italian while being comparable in English. 3.3 Long-range performance As shown in figure 4, the input context length of language models has increased by several orders of magnitude in the last few years - from 512 tokens for the BERT model to 200k tokens for Claude 2. However, most large language models struggle to efficiently use the longer context. Nelson and colleagues showed that current language models do not robustly make use of information in long input contexts, and their performance is typically highest when the relevant information for tasks such as question-answering or key-value retrieval occurs at the beginning or the end of the input context, with significantly degraded performance when the the models need to access information in the middle of long contexts. Mixtral, which has a context size of 32k tokens, overcomes this deficit of large language models and shows 100% retrieval accuracy regardless of the context length or the position of the key to be retrieved in a long context. The perplexity, a metric that captures the capability of a language model to predict the next word given the context, decreases monotonically as the context length increases. Lower perplexity implies higher accuracy, and the Mixtral model is therefore capable of extremely good performance on tasks based on long context lengths as shown in figure 5. 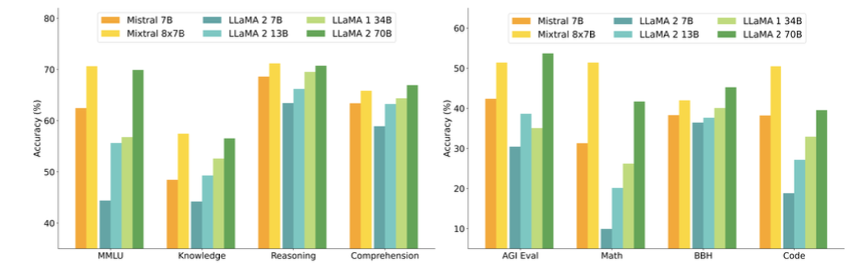 Figure 3. Performance of Mixtral in comparison to Llama 1 and 2 models of different sizes. 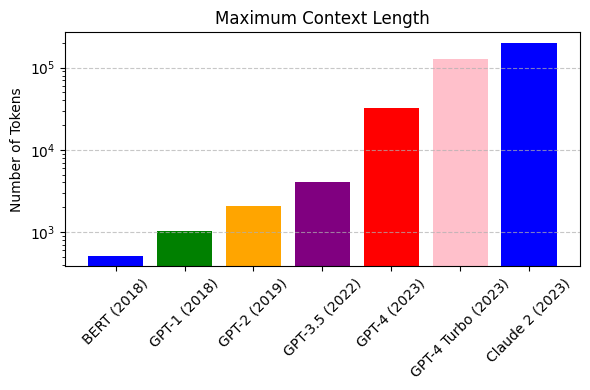 Figure 4. Evolution of the context length of large language models. 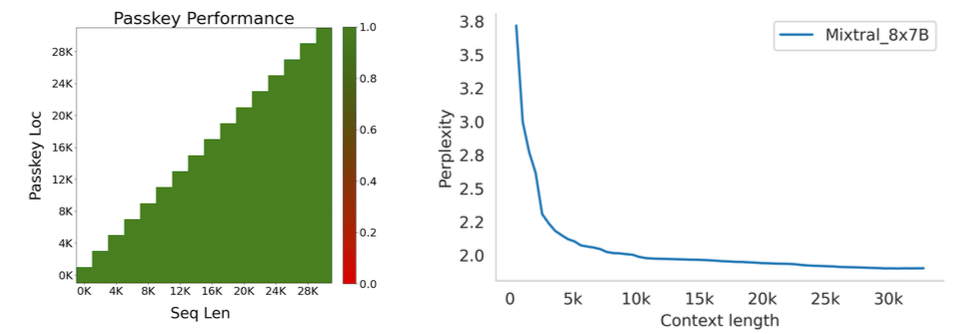 Figure 5. Long range performance of Mixtral. 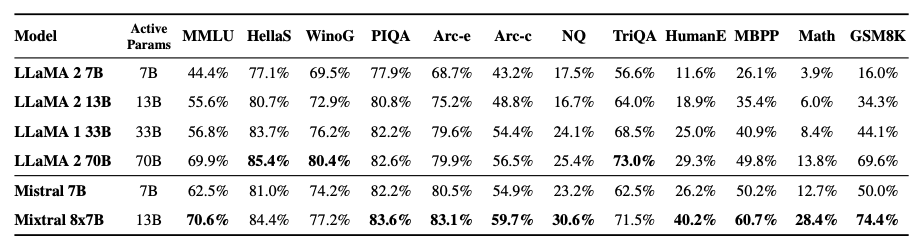 Table 1. Mixtral outperforms Llama 2 70B model on almost all benchmarks while using less than 1/5th of the active parameters during inference. 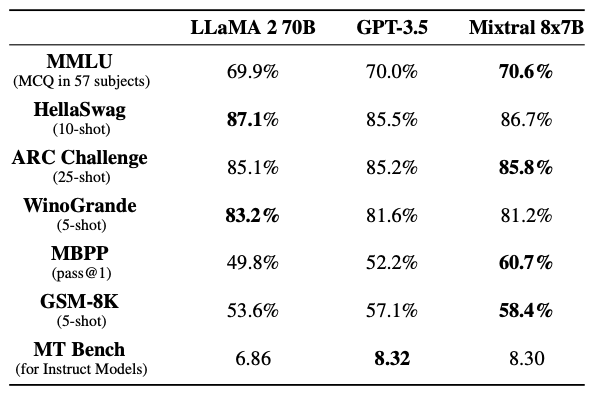 Table 2. Mixtral outperforms or matches the performance of Llama 2 70B and GPT-3.5 on most benchmarks.  Table 3. Mixtral’s performance on multilingual benchmarks for French, German, Spanish and Italian versus Llama 1 and 2 models. 4. Instruction Fine-tuning Instruction tuning refers to the process of further training large language models on a curated dataset containing (instruction, output) pairs of training samples. Instruction tuning is a computationally efficient method for extending the capabilities of large language models in diverse domains without extensive retraining or architectural changes. “Mixtral - Instruct” model was fine-tuned on an instruction dataset followed by Direct Preference Optimization (DPO) on a paired feedback dataset. DPO is a technique to optimize large language models to adhere to human preferences without explicit reward modeling or reinforcement learning. As of January 26, 2024, on the standard LMSys Leaderboard, Mixtral - Instruct continues to be the best performing open-source large language model. This leaderboard is a crowdsourced open platform for evaluating large language models that ranks models following the Elo ranking system in chess. Mixtral - Instruct only ranks below proprietary models like OpenAI’s GPT-4, Google’s Bard and Anthropic’s Claude models, while being a significantly small model. This extremely strong performance of Mixtral - Instruct and with an open-source friendly Apache 2.0 license opens up the possibility for tremendous adoption of Mixtral for both commercial and non-commercial applications. It represents a much more powerful alternative to Llama 2 70B that is already being used as the foundational model for extending large language models to other languages like Hindi or Tamil that are spoken widely but not adequately represented in the training dataset of these large language models. 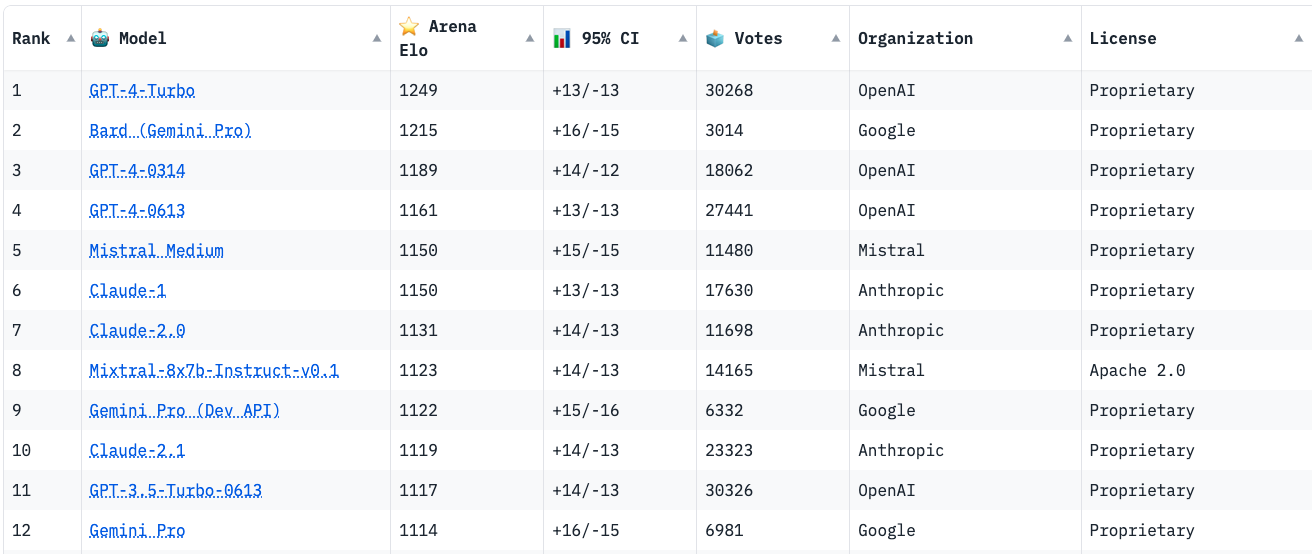 Figure 6. Mixtral is the best performing open-source large language model on the LMSys Leaderboard. 5. Use Cases
Mixtral represents the numero uno of open-source large language models as it clearly outperforms the previous best open-source model, Llama 2 70B, by a significant margin, while providing for faster and cheaper inference. At the time of writing this article, Mixtral has been available in the open-source for less than two months and we are yet to see many examples of how it is being used in the industry. However, there are some early movers, like the Brave browser that has already incorporated Mixtral in its AI-based browser assistant, Leo. Mixtral is also incorporated by Brave for powering its [programming-related queries in Brave Search. It is only a matter of time before Mixtral witnesses widespread adoption across industry for a variety of use cases and challenges the hegemony of proprietary models like OpenAI’s GPT-4 and the likes. 6. Conclusion Mixtral is a cutting-edge, mixture-of-experts model with state-of-the-art performance among open-source models. It consistently outperforms Llama 2 70B on a variety of benchmarks while having 5x fewer active parameters during inference. It thus allows for a faster, more accurate and cost-effective performance for diverse tasks including mathematics, code generation, as well as multilingual understanding. Mixtral - Instruct also outperforms proprietary models such as Gemini-Pro, Claude-2.1, GPT-3.5 Turbo on human evaluation benchmarks. Mixtral thus represents a powerful alternative to the much larger and more compute intensive Llama 2 70B as the de facto best open-source model, and will facilitate development of new methods and applications benefitting a wide variety of domains and industries.
Comments
Introduction
Consumer technology companies like Amazon, Yelp, and Airbnb are focused on providing an impeccable customer experience, and reviews are integral to that experience. Reviews from previous customers can signal trust and reliability (e.g., total number of reviews or average star rating), empowering first-time buyers or new customers in their decision-making. Millions of reviews are shared on platforms like Amazon for e-commerce products, on Airbnb for travel and hospitality, on Glassdoor for company and employment experience, and on Google for third-party businesses. However, the internet has become rife with fake reviews. Fake reviews and inflated ratings provide a tainted picture of a product or service and are designed to trick customers away from or toward certain purchases. As these reviews are an important input factor for search and ranking algorithms, they can have a massive influence on product discovery and sales. This provides a strong incentive for bad actors to try to manipulate the system by improving the ratings of their products through fake reviews. There is a booming market for fake reviews, which are purchased via multiple social media and community platforms. The problem is enormous - nearly four percent of all reviews are fake, translating into a global economic impact of USD 152 billion. E-commerce companies like Amazon spend upwards of a billion dollars and employ tens of thousands of workers to combat online fraud and abuse. Some companies use sophisticated technologies including AI to detect and delete fake reviews, but their accuracy is limited (less than forty percent) and it often takes more than one hundred days to remove those reviews. During that time, fraudulent sellers can make strong short-term revenues and profits. Apart from the short-term commercial losses, there is a longer-term problem; fake reviews erode customer trust and safety, causing customers to avoid online purchases. Catching fake reviews is therefore paramount for a majority of online marketplaces and businesses. Characteristics of Fake Reviews Fake reviews have several telltale characteristics. For instance, as they are based on a fraudulent experience with the product or service, fake reviews will often focus on a poor customer experience without specific details about that product or service. Another sign is the repetition of positive or negative keywords and text. As it is difficult to fabricate a review, fake reviewers keep emphasizing certain keywords and details to paint a terrible customer experience. Such reviews accentuate extreme details without providing a balanced perspective. Fake reviewers also excessively use emoticons and exclamation points in an attempt to appeal to the customers’ emotions. Genuine reviewers tend to focus more on information and provide thoughtful, actionable feedback for other customers about the product experience. One clear giveaway is the reviewer’s name and avatar. Fake reviews are usually submitted using an account with a dubious username, avatar, or email address. If a reviewer seems like they could be illegitimate, check whether they have shared any reviews previously, how often, and for which products or businesses. Fake accounts are often created for one-time use, and fake reviewers can submit multiple reviews in a short span of time, sometimes on the same day. Sometimes fake reviewers post a poor rating without any comments to describe their experience. Genuine reviewers take the time and effort to write useful feedback. Spotting these characteristics can help you find many fake reviews, but scamsters are always devising more sophisticated techniques to replace those that have already been detected through algorithms, AI, or human reviewers. One solution to this problem is fingerprinting technology, that can identify unique users of your website regardless of VPNs, cookie blockers, private browsing, or other tools. They use data including the browser and device used, usage patterns, IP addresses, and geolocation to create a unique identifier for site visitors, making it easier to spot users trying to hide their identity or committing fraudulent activity. Conclusion Fake reviews have undermined the revenue and growth of online sellers and small businesses. These reviews can boost the sales of a poor product by exaggerating its positive rating, or damage the sales of competitor products via negative reviews. While there are ways to catch these fake reviewers in the act, it’s an increasingly sophisticated scam and a headache for businesses. Fingerprinting technology can help you find and remove fake reviews as well as protect your business from all types of online fraud. This helps ensure that your customers will have a safe and reliable online shopping experience. Recently, the Government of India issued a draft framework of standards to counter fake reviews in order to reduce their prevalence on e-commerce platforms. Related Blog Published in Towards Data Science Preview:
TLDR (or TL;DR) is a common internet acronym for “Too Long; Didn’t Read.” It likely originated on the comedy forum Something Awful around 2002 (source) and then became more popular in online forums like Reddit. It is often used in social media where the author or commenters summarise lengthy posts and provide a TLDR summary of one or two lines as a courtesy to other readers. TLDRs help readers get the gist of the information and enable quick informed decisions on whether to invest the time in reading the full post. With Natural language processing (NLP) and automatic text summarization systems, TLDR generation can be automated. Automatic text summarization is a challenging problem of generating a shorter summary of a long document while preserving its essence. It has wide practical applications in multiple domains such as legal contract analysis, search (summarising use information in websites, entity-centric summarization from Wikipedia articles), question answering systems, media (generating news headlines, summarising articles in newsletters), marketing (generating copy, slogans) among others. Automatically generated text summaries help reduce reading time, are non-biased compared to human authored summaries, and could also be beneficial for a lot of personal day to day applications like email summarization, TLDR generation for posting on social media sites like Twitter, and more. 👉 Here is the full article Published in Towards Data Science Introduction
Electronic means of communication have helped to eliminate time and distance barriers to sharing and broadcasting information. However, despite all its advantages, faster means of communication have also resulted in the extensive spread of misinformation. The world is currently going through the deadly COVID-19 pandemic and fake news regarding the disease, its cures, its prevention, and causes have been broadcast widely to millions of people. The spread of fake news and misinformation during such precarious times can have grave consequences leading to widespread panic and amplification of the threat of the pandemic itself. As per a recent BBC report from August 2020, at least 800 people may have died around the world because of coronavirus-related misinformation in the first three months of this year. It is therefore of paramount importance to limit the spread of fake news and ensure that accurate knowledge is disseminated to the public. In this blog, we explore the problem of fake news detection related to COVID-19 and describe our approach to tackle it using Natural Language Processing. This is based on our recent paper — ‘Two Stage Transformer Model for COVID-19 Fake News Detection and Fact Checking’, accepted at the NLP for Internet Freedom Workshop, co-located with COLING2020. Our NLP solution: We built a topical fake news detection system capable of verifying claims as well as providing explanations, all in real-time. Developing a solution for such a task involves generating a database of factual explanations, which constitutes our knowledge base, that serves as ground truth for any given claim. We computed the entailment between any given claim and explanation to verify whether the claim is true or not. Querying for claim-explanation pairs for each explanation in our knowledge base is computationally expensive and slow, so we propose generating a set of candidate explanations that are contextually similar to the claim. We achieved this by using a model trained with relevant and irrelevant claim-explanation pairs and using a similarity metric between the two to match them. Previous research on fake news detection Previous work on fake news detection has primarily focused on evaluating the relationship measured via a textual entailment task between a header and the body of the article. Researchers have explored the use of simple classifier models with TF-IDF features and cosine similarity metric to classify fake news. Several baselines with such methods exist on standard datasets like FNC-1 and FEVER. Transformer based pre-trained models achieved state of the art results in several NLP subtasks, their ease of fine-tuning makes them adaptable to newer tasks. In further related work, the authors proposed a model based on the BERT architecture to detect fake news by analyzing the contextual relationship between the headline and the body text of news. They further enhanced their model performance by pre-training with domain-specific news and articles. The use of social media has also been extensively studied for stopping misinformation for Covid-19. In a related work to this, authors developed an Infodemic Risk Index (IRI) after analyzing Twitter posts across various languages and calculated the rate at which a particular user from a locality comes across unreliable posts from different classes of users like verified humans, unverified humans, verified bots and unverified bots. But none of these mentioned works tackles the problem of misinformation by reasoning out the given fake claim with an explanation. Datasets: The use of an existing misinformation dataset would not serve as a reliable knowledge base for training and evaluating the models due to the recent and uncommon nature i.e., the vocabulary used to describe the disease and the terms associated with the COVID-19 pandemic. It was therefore important to generate real and timely datasets to ensure accurate and consistent evaluation of the methods. To overcome this drawback, we manually curated a dataset specific to COVID-19. Our proposed dataset consists of 5500 claim and explanation pairs. There are multiple sources on the web that are regularly identifying and debunking fake news on COVID-19. We collected data from “Poynter”, a fact checking website which collects fake news and debunks or fact-checks them with supporting articles from more than 70 countries. For each fact check, we collected only the ”claim” and the corresponding “explanation” from this database which were rated as ’False’ or ’Misleading’. In this way, we collected about 5500 false-claim and explanation pairs. We further manually rephrased a few of these false claims to generate a true claim, as the ones that aligned with the explanation, so as to create an equal proportion of true-claim and explanation pairs. Model Architecture: The architecture consists of a two stage model, we will refer to the first model as “Model A” and the second model as “Model B”. The objective of Model A is to fetch the candidate “true facts” or explanations for a given claim, which are then evaluated for entailment using Model B. Model A is trained on all claim-explanation pairs, as we have a lot more of them, and the task of the Model A is to pick out candidate claims for a given explanation. Model A is trained on a Next Sentence Prediction (NSP) task. Through our experiments, we find that, on this trained model, if we generate embeddings for a single sentence (either claim or explanation individually) and compare matching [claim, explanation] embeddings using the cosine similarity metric, there is a distinction in the distribution of similarity scores between related and unrelated [claim, explanation] pairs. Therefore, for faster near real-time performance, we cache the embeddings for all our explanations (knowledge base) beforehand and compute the cosine similarity between the claim and the cached embeddings of the explanations. We fetch the top explanations for any given claim exceeding a certain threshold of sentence similarity as there could be several explanations relevant for a given claim. The second part of the pipeline is to identify the veracity of a given claim. Model A fetches the candidate explanations while Model B is used to verify whether the given claim aligns with our set of candidate explanations or not. To train Model B, we use a smaller subset of “false claim” and “explanation” pairs from our original dataset, and cross-validate each sample with “true claim” or in other words, claims that align with the factual explanation. However, this small annotated data is not sufficient to train the model effectively. Therefore, the parameters of the Model A, which was trained on a much larger dataset were used as initial parameters for Model B, and fine-tuned further using our cross-validated dataset. Model B is also trained for the sequence classification task. Essentially Model B computes the entailment between its input claim, explanations pairs. We trained and evaluated both Model A and Model B using several approaches based on classical NLP methods as well as more sophisticated pre-trained Transformer models. The flow of the Model A + Model B pipeline is shown in the above figure. Transformer based Models: We trained and evaluated three Transformer based pre-trained models for both Model A and Model B using the training strategy described before. As our focus was to ensure that the proposed pipeline can be deployed effectively in a near real-time scenario, we restricted our experiments to models that could efficiently be deployed using inexpensive compute. We chose the following three models — BERT(base), ALBERT, and MobileBERT. Model A was trained on 5000 claim-explanation pairs on the sequence classification task to optimize the softmax cross entropy loss. This trained model was then validated on a test set comprising 1000 unseen claim-explanation pairs. The training data structure here looks like this. [claim, relevant explanation, 1], [claim, irrelevant explanation, 0] Model B was trained on a smaller subset of 800 cross-validated [claim, explanation, label] data, on the same sequence classification task, where the label was assigned based on whether the claim aligned with the explanation — 1 or not — 0. This was validated on 200 unseen data-points. The loss function used was softmax cross-entropy. The training data structure here looks like: [true claim, relevant explanation, 1] [false claim, relevant explanation, 0] For baselining we implement classical NLP approaches in our use-case and compare those results with transformer based models. We implement GLoVeand TF-IDF architectures for the classical ones. Evaluation metrics: For evaluating the performance of the overall pipeline model, we first evaluate the performance of Model A in its ability to retrieve relevant explanations. For this we use Mean Reciprocal Rank(MRR) and Mean Recall@10, that is, the proportion of claims for which the relevant explanation was present in the top 10 most contextual explanation by cosine similarity and their mean inverse rank. Once, Model A has retrieved relevant explanations, we evaluate the performance of Model B on computing the veracity of the claim. Here, we only used explanations that exceed an empirically defined threshold in cosine similarity between the query claim and the explanation. Through our experiments, we found that a threshold of the mean standard deviation of cosine similarity over the validation data worked well for picking relevant explanations. For evaluating the accuracy, we take a mean of the output probabilities for each claim, explanationᵢ. This is expected due to the lower parameter size of the TF-IDF and GloVe models. Among the Transformer based models, MobileBERT had the least latency per claim as expected while ALBERT consumed the least memory. The best performing BERT+ALBERT model utilized a memory of 1398MB and fetched relevant explanations of each claim in 2.471 seconds. The model latencies and memory usage were evaluated on an Intel Xeon — 2.3GHz Single-core — 2 thread CPU. Observations: We however do acknowledge that our models could still make errors of two kinds: Firstly, Model A might not fetch a relevant explanation which automatically means that the prediction provided by Model B is irrelevant, and secondly, Model A might have fetched the correct explanation(s) but Model B classifies it incorrectly. We show some of the errors our models made in this table. Conclusions: In this work, we have demonstrated the use and effectiveness of pre-trained Transformer based language models in retrieving and classifying fake news in a highly specialized domain of COVID-19. Our proposed two stage model performs significantly better than other baseline NLP approaches. Our knowledge base, which we prepare through collecting factual data from reliable sources from the web can be dynamic and change to a large extent, without having to retrain our models again for as long as the distribution is consistent. All of our proposed models can run in near real-time with moderately inexpensive compute. Our work is based on the assumption that our knowledge base is accurate and timely. This assumption might not always be true in a scenario such as COVID-19 where “facts” are changing as we learn more about the virus and its effects. Therefore a more systematic approach is needed for retrieving and classifying claims using this dynamic knowledge base. Future Work: Our future work consists of weighting our knowledge base on the basis of the duration of the claims and benchmarking each claim against novel sources of ground truth. Our model performance can be further boosted by better pre-training, through domain specific knowledge. In one of the more recent work, the authors propose a novel semantic textual similarity dataset specific to COVID-19. Pre-training our models using such specific datasets could help in a better understanding of the domain and ultimately better performance. Fake news and misinformation is an increasingly important and difficult problem to solve, especially in an unforeseen situation like the COVID-19 pandemic. Leveraging state of the art machine learning and deep learning algorithms along with preparation and curation of novel datasets can help address the challenge of fake news related to COVID-19 and other public health crises. Published in Towards Data Science Introduction
In recent years, the amount of data powering different industries, and their systems has been increasing exponentially. Majority of business information is stored in the form of relational databases that store, process, and retrieve data. Databases power information systems across multiple industries, for instance, consumer tech (e.g. orders, cancellations, refunds), supply chain (e.g. raw materials, stocks, vendors), healthcare (e.g. medical records), finance (e.g. financial business metrics), customer support, search engines, and much more. It is imperative for modern data-driven companies to track the real-time state of its business in order to quickly understand and diagnose any emerging issues, trends, or anomalies in the data and take immediate corrective actions. This work is usually performed manually by business analysts who compose complex queries in declarative query languages like SQL to derive business insights stored in multiple tables. These results are typically processed in the form of charts or graphs to enable leadership teams to quickly visualize the results and facilitate data-driven decision making. Although the most common SQL queries that address fundamental business metrics are predefined and incorporated in commercial products like PowerBi that power insights into business metrics, any new or follow-up business queries still need to be manually coded by the analysts. Such static interactions between database queries and consumption of the corresponding results require time-consuming manual intervention and result in slow feedback cycles. It is vastly more efficient to have non-technical business leaders directly interact with the analytics tables via natural language queries that abstract away the underlying SQL code. Defining the SQL query requires a strong understanding of database schema, SQL syntax and can quickly get overwhelming for beginners and non-technical stakeholders. Efforts to bridge this communication gap have led to the development of a new type of processing called Natural Language Interface to Database (NLIDB). This natural search capability has become more popular over recent years as companies such as Microsoft [1][2], Salesforce [3][4], and others are developing similar technologies for Natural language (NL) to SQL (NL2SQL). The converted SQL could also enable virtual assistants like Alexa, Google Home, and others to improve their responses when the answer can be found in different databases or tables. This blog will review the challenges, evaluation methods, datasets, different approaches, and some state-of-the-art deep learning approaches for NL2SQL. 2. Technical challenges 2.1 Understanding NL query and aligning utterance with schemaThe system must understand both the user’s question and the table schemas (columns, table names, and values) to map the query to SQL correctly. A key challenge here is understanding the structured schema of DB tables (e.g., the name, data type, and stored values of columns) and the alignment between the input query and the schema. For instance, for the question, Which country has the largest GDP?, the model needs to map GDP to the Gross Domestic Product Column. Sometimes the question might also require understanding the semantics of a column rather than just column names. For the table and question shown in Figure 3, the Venue column used to answer the example question refers to host cities. Hence, the model needs to align “city” in the query with the venue column in the table. 2.2 Generalization to cross-domains Collecting large training data for different domains is expensive and non-scalable. Hence, it is important to train systems to generalize to different domains and databases. This generalization would involve identifying new entities, mapping unseen phrases and entities correctly in the SQL query, and handling novel database and query structures (larger tables, the composition of SQL components, etc.)[5]. 2.3 Order matters problem One of the standard ways to solve the NL2SQL tasks is to use seq2seq (since both NL query and SQL are sequences) models and their variants. One of the issues with this approach is that different SQL queries may be equivalent to each other due to commutative and associative properties. 3. Datasets There are several datasets for NL2SQL tasks. These contain annotated NL questions, SQL pairs corresponding to one or more tables. These datasets differ in terms of domains (single vs. cross-domain), size (number of queries — which is essential for proper model evaluation), and query complexity (single table vs. multi-table). The early datasets like ATIS, GeoQuery focus on single domains and are also limited in terms of the number of queries. Some of the latest datasets like WikiSQL, Spider are cross-domain, and context-independent with a larger size. One significant difference between WikiSQL and Spider is query complexity. Queries in WikiSQL are simpler (which only covers SELECT and WHERE clauses). Also, each database in WikiSQL is only a simple table without any foreign key. Spider contains a modest number of queries and includes complex questions that involve joins of tables and nested queries. The SParC[15] and CoSQL[16] are the extensions of the Spider dataset that are created for contextual cross-domain semantic parsing and conversational dialog text-to-SQL system. 4. Evaluation methods The most common methods to evaluate NL2SQL systems are execution accuracy and logical form accuracy. Execution accuracy compares the result after execution of the predicted SQL query with the result of the ground truth query. One downside of this method is that it is possible to have an unrelated SQL query that does not correspond to the question but still gives the right answer (for example, NULL result). Logical form accuracy compares the exact string match of predicted SQL query with the ground truth query. This metric has the limitation of incorrectly penalizing predictions that yield correct results upon execution but do not have an exact string match with a ground truth SQL query. One approach to solving the ordering issue is to canonicalize SQL queries before comparison [17]. SQL canonicalization is a method to make evaluations consistent by ordering columns in SELECT, tables in FROM, and WHERE constraints and standardizing table aliases, capitalization, and space between symbols. Authors of Spider [19] use component matching, which measures the average exact match between the prediction and ground truth on different SQL components like SELECT, WHERE, GROUP BY, etc. The prediction and ground truth is parsed and decomposed into subcomponents and then their exact match is calculated component-wise. For example, to evaluate the SELECT component: SELECT avg(col1), max(col2), min(col1) is decomposed to set (avg, min, col1), (max, col2) And then this set is compared with the ground truth sets. Even though this takes care of the ordering issue, it still does not account for when the prediction uses a different logic (compared to ground truth SQL) to arrive at the same result. Hence for a thorough evaluation, execution accuracy should also be used. The authors in [19] also categorize query by hardness based on the number of SQL components, selections, and conditions. This categorization can be very helpful for getting more insights about model performance with respect to query complexity. 5. Different approaches for NL2SQL 5.1 Rule-based approachesMost existing approaches focus on a rule-based parser for natural language combined with ambiguity detection. Some rule-based systems use trigger words to identify patterns in the user’s question. For example, “by” is a common word used in aggregation queries like “List the movies directed by <director>”. Here, the trigger word’s left side might have the keywords required for the SELECT clause, and the right side would have the necessary keywords for the GROUP BY clause. Despite its simplicity, this approach (if rules are well-formed) has been shown to handle a surprisingly broad type of queries. Modern conversational agents such as Siri and Cortana follow a similar principle, although the rules are not deterministic and based on training (logistic regression classifier of intent). 5.2 Grammar-based systemsIn Grammar-based systems, the user’s question is parsed, and the resulting parsed tree is directly mapped to expression in SQL. A grammar is created which can describe the possible syntactic structures of the user’s questions. The over-simplistic grammar shown in the figure considers the user’s question(S) to be composed of Noun Phrase and a Verb Phrase; Noun phrases consist of a Determiner followed by Noun, Determiner consists of the word “What” or “Which” etc. This grammar can then be used to parse a question like “Which rock contains magnesium?” into a parse tree and then map the resulting parse tree to SQL. This mapping back to SQL would be carried out by rules and based entirely on the parse tree’s syntactic information. 5.3 Deep Learning based-approachesRule-based approaches are limited in terms of coverage, scalability, and naturalness. They are also not robust to natural language diversity and are very difficult to scale across domains. The advent of large scale supervised datasets like WikiSQL, Spider, etc., and advances in Natural language processing, pretraining [20], etc. has enabled Deep learning models to achieve the state of the art results in NL2SQL tasks. Almost all the deep learning models generate the SQL query from natural language input with an encoder-decoder [21] model. The encoder could be RNN [22] / LSTM [24] or the recent transformer [25] networks. Most of the models differ in how they encode the schema (table names, column names, cell values, etc.) and how they produce the SQL output. Some models make schema as part of their output vocabulary. In other words, they put all the table names, column names, etc., into their output vocabulary, and while decoding the SQL output, they select these words from the vocabulary. NSP[10], DBPAL[18] are some of the methods which use this approach. One major limitation of this approach is we cannot adapt them to cross-domains as they do not encode new schemas in their input. In contrast, other methods like SEQ2SQL[3] use the schema as input to the model and while decoding, use the table or column names mentioned in the input using pointer networks [26]. For instance, in SEQ2SQL[3], the authors use column names, question tokens, and SQL tokens like SELECT, WHERE, COUNT, MIN, MAX, etc. as input. Their pointer network produces the SQL query by selecting exclusively from this augmented input sequence. The authors also claim that apart from limiting the output space, this augmented pointer network produces higher quality WHERE clauses. Based on the generation of SQL queries from natural language input, there exist three types of models: sequence to sequence, sequence to tree, and slot-filling[23]. The sequence to sequence models generates the SQL as a sequence of words. The sequence to tree models generates a syntax tree of the predicted SQL query. The slot-filling methods treat the SQL query as a set of slots and then decode the whole question using relevant decoders for each slot. An advantage of grammar-based decoders is that they can check for grammatical errors at every step, producing complex queries with joins, nested queries, etc. without any syntax errors. 5.4 Modern Deep Learning approaches Modern Deep Learning approaches use more techniques to learn joint representations over NL questions and structured information present in tables. They use various attention-based architectures for question/schema encoding and AST based structure architecture (sequence to tree) for query decoding. IRNet [1], RAT-SQL (current SOTA approach in spider) [2] use BERT[21] (for NL representation) along with in-house strategies to encode structured information in tables. In contrast, TaBERT[27] uses a general-purpose pretraining approach to learn representations of natural language sentences and tabular data. These techniques include schema linking, better schema encoding, using DB content (Cell values instead of just column and table names), contextualizing questions and schema representations. 5.4.1 Schema Linking This involves aligning the entity references in the question to the right schema columns or tables. Textual matches are the best evidence for question-schema alignment, and it might be directly beneficial to the encoder. Linking is generally done with string matching in IRNet and RAT-SQL. N-grams (up to lengths of 5 or 6) in the question are used to match (both exact matches and partial matches are considered) column or table names in the schema. After linking, IRNet tags each entity mentioned in the question with the type of the corresponding entity (table name/column name, etc.) while encoding. The column names are also assigned types EXACT MATCH and PARTIAL MATCH based on n-gram overlap with question words. RAT-SQL, on the other hand, constructs a graph with question words and the column/table names as the nodes and edges being QUESTION-COLUMN-M, QUESTION-TABLE-M, etc., where M is either one of EXACTMATCH, PARTIALMATCH, or NOMATCH. 5.4.2 Value-based linking The natural language question can also have value mentions (like ‘4’ in ‘For cars with 4 cylinders, which model has the largest horsepower’), which would be present as a cell value in some table. IRNet looks up the value mention from the question in a knowledge base and searches the results returned over the column names for partial or exact matches. The column names are assigned types VALUE EXACT MATCH and VALUE PARTIAL MATCH based on the match. RAT-SQL, on the other hand, adds an edge COLUMN-VALUE between question word and a column name if the question word occurs as a value in the column. TaBERT uses the DB content directly instead of linking and using the column name. The authors reason that contents provide more detail about a column’s semantics than just the column’s name, which might be ambiguous. They select a content snapshot consisting of only a few rows that are most relevant based on string matching (n-gram overlap) to the NL question. 5.4.3 Schema Encoding This involves encoding the relational structure in databases. It is much more challenging in databases with multi-table relations (where encoding primary, foreign keys, etc. are essential). IRNet encodes both the columns and tables to get column and row representations. The columns are represented by column name and their type, which is defined from schema linking. The final representations are created by adding the column name embeddings, context embeddings (based on n-grams matched in the question), and type embeddings. RAT-SQL represents the schema as a directed graph with columns and tables as nodes. The edges are defined by database relations detailed in the above diagram. 5.4.4 Contextualizing question and schema representations This helps in learning effective joint representations. RAT-SQL augments their schema graph by adding edges between question words and schema entities defined after schema linking. They introduce a relation-aware self-attention[25] layer to use the relational structure in the input and also learn “soft” relations between the sequence elements. They do this by providing a way to communicate known relations (like primary key, foreign keys, etc. defined in edge labels) by adding their representations to the attention. 6. Conclusions and Future trends In this blog, we reviewed the state-of-the-art in NL2SQL — the problem statement, challenges, evaluation of such systems, and the modern machine learning techniques for solving the task. Recent work also focuses on improving the user experience while using such systems. Photon [4] is a flexible system that supports both NL questions and SQL as input. It also has a confusion detection module that detects unanswerable questions and helps users paraphrase a question to get the right answers. Authors in [28] also show that incorporating human feedback can further improve the accuracy and user experience of these systems. Although modern NL2SQL techniques achieve good accuracy on benchmark test sets, they are still far from demonstrating robust performance in production settings. In the context of business decision making, it is critical to achieving reliable performance to foster and build users’ trust in such systems. NL2SQL methods have the potential to significantly enhance the efficiency of human analysts so they can focus more time on contextual interpretation and validation of results. The output of modern end-to-end deep learning systems suffer from a lack of interpretability, and while there is significant research on how AI systems work under the hood, incorporating humans-in-the-loop to provide feedback and improve the predictive power will accelerate the adoption and use of NL2SQL systems across the modern data-driven organizations. 7. References [1] Guo, Jiaqi, et al. “Towards complex text-to-sql in cross-domain database with intermediate representation.” (2019) arXiv preprint arXiv:1905.08205 [2] Wang, Bailin, et al. “Rat-sql: Relation-aware schema encoding and linking for text-to-sql parsers.” (2019) arXiv preprint arXiv:1911.04942 [3] Zhong, Victor, Caiming Xiong, and Richard Socher. “Seq2sql: Generating structured queries from natural language using reinforcement learning.” (2017) arXiv preprint arXiv:1709.00103 [4] Zeng, Jichuan, et al. “Photon: A Robust Cross-Domain Text-to-SQL System.” (2020) arXiv preprint arXiv:2007.15280 [5] Suhr, Alane, et al. “Exploring Unexplored Generalization Challenges for Cross-Database Semantic Parsing.” (2020) Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. [6] Dahl, Deborah A., et al. “Expanding the scope of the ATIS task: The ATIS-3 corpus.”(1994) HUMAN LANGUAGE TECHNOLOGY: Proceedings of a Workshop held at Plainsboro, New Jersey, March 8–11, 1994. [7] Tang, Lappoon R., and Raymond J. Mooney. “Using multiple clause constructors in inductive logic programming for semantic parsing.”(2001) European Conference on Machine Learning. Springer, Berlin, Heidelberg, 2001. [8] Tang, Lappoon R., and Raymond Mooney. “Automated construction of database interfaces: Integrating statistical and relational learning for semantic parsing.” (2000) Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora. [9] Li, Fei, and H. V. Jagadish. “Constructing an interactive natural language interface for relational databases.” (2014) Proceedings of the VLDB Endowment 8.1: 73–84. [10] Iyer, Srinivasan, et al. “Learning a neural semantic parser from user feedback.” (2017) arXiv preprint arXiv:1704.08760 [11] Yaghmazadeh, Navid, et al. “SQLizer: query synthesis from natural language.” (2017) Proceedings of the ACM on Programming Languages 1.OOPSLA: 1–26. [12] Zhong, Victor, Caiming Xiong, and Richard Socher. “Seq2sql: Generating structured queries from natural language using reinforcement learning.” (2017) arXiv preprint arXiv:1709.00103 [13] Finegan-Dollak, Catherine, et al. “Improving text-to-sql evaluation methodology.” (2018) arXiv preprint arXiv:1806.09029 [14] Yu, Tao, et al. “Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task.” (2018) arXiv preprint arXiv:1809.08887 [15] Yu, Tao, et al. “Sparc: Cross-domain semantic parsing in context.” (2019) arXiv preprint arXiv:1906.02285 [16] Yu, Tao, et al. “Cosql: A conversational text-to-sql challenge towards cross-domain natural language interfaces to databases.” (2019) arXiv preprint arXiv:1909.05378 [17] Finegan-Dollak, Catherine, et al. “Improving text-to-sql evaluation methodology.” (2018) arXiv preprint arXiv:1806.09029 [18] Basik, Fuat, et al. “Dbpal: A learned nl-interface for databases.” (2018) Proceedings of the 2018 International Conference on Management of Data [19] Yu, Tao, et al. “Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task.” (2018) arXiv preprint arXiv:1809.08887 [20] Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” (2018) arXiv preprint arXiv:1810.04805 [21] Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. “Sequence to sequence learning with neural networks.” (2014) Advances in neural information processing systems. [22] Williams, Ronald J.; Hinton, Geoffrey E.; Rumelhart, David E. “Learning representations by back-propagating errors”. (October 1986) Nature. [23] Kim, Hyeonji, et al. “Natural language to SQL: where are we today?.” (2020) Proceedings of the VLDB Endowment 13.10: 1737–1750. [24] Hochreiter, Sepp; Schmidhuber, Jürgen “Long Short-Term Memory”. (1997–11–01) Neural Computation. [25] Vaswani, Ashish, et al. “Attention is all you need.” (2017) Advances in neural information processing systems. [26] Vinyals, Oriol, Meire Fortunato, and Navdeep Jaitly. “Pointer networks.” (2015) Advances in neural information processing systems. [27] Yin, Pengcheng, et al. “TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data.” (2020) arXiv preprint arXiv:2005.08314 [28] Elgohary, Ahmed, Saghar Hosseini, and Ahmed Hassan Awadallah. “Speak to your Parser: Interactive Text-to-SQL with Natural Language Feedback.” (2020) arXiv preprint arXiv:2005.02539 |
Archives
March 2024
Categories
All
Copyright © 2024, Sundeep Teki
All rights reserved. No part of these articles may be reproduced, distributed, or transmitted in any form or by any means, including electronic or mechanical methods, without the prior written permission of the author. Disclaimer
This is a personal blog. Any views or opinions represented in this blog are personal and belong solely to the blog owner and do not represent those of people, institutions or organizations that the owner may or may not be associated with in professional or personal capacity, unless explicitly stated. |
 RSS Feed
RSS Feed