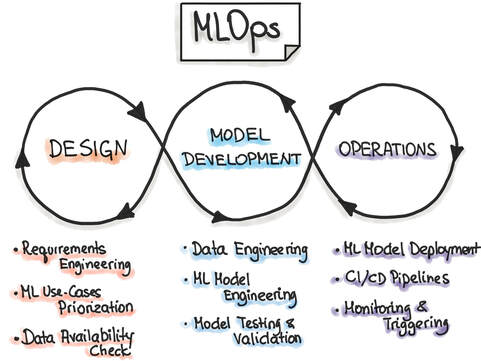
 Source: MLOps Org Machine learning operations (MLOps) refer to the emerging field of delivering machine learning models through repeatable and efficient workflows. The machine learning lifecycle is composed of various elements, as shown in the figure below. Similar to the practice of DevOps for managing the software development lifecycle, MLOps enables organizations to smooth the path to successful AI transformation by providing an engineering and technological backbone to underlying machine learning processes.
MLOps is a relatively new field, as the commercial use of AI at scale is itself a fairly new practice. MLOps is modeled on the existing field of DevOps, but in addition to code, it incorporates additional components, such as data, algorithms, and models. It includes various capabilities that allow the modern machine learning team, comprising data scientists, machine learning engineers, and software engineers, to organize the building blocks of machine learning systems and take models to production in an efficient, reliable, and reproducible fashion. MLOps tools MLOps is carried out using a diverse set of tools, each catering to a distinct component of the machine learning pipeline. Each tool under the MLOps umbrella is focused on automation and enabling repeatable workflows at scale. As the field of machine learning has evolved over the last decade, organizations are increasingly looking for tools and technologies that can help extract the maximum return from their investment in AI. In addition to cloud providers, like AWS, Azure, and GCP, there are a plethora of start-ups that focus on accommodating varied MLOps use cases. In this article, I will cover tools for the following MLOps categories:
In the following section, I will list a selection of MLOps tools from the above categories. It is important to note that although a particular tool might be listed under a specific category, the majority of these tools have evolved from their initial use case into a platform for providing multiple MLOps solutions across the entire ML lifecycle. Metadata Management Building machine learning models involves many parameters associated with code, data, metrics, model hyperparameters, A/B testing, and model artifacts, among others. Reproducing the entire ML workflow requires careful storage and management of the above metadata. Featureform Featureform is a virtual feature store. It can integrate with various data platforms, and it enables the management and governance of the data from which features are built. With a unique, feature-first approach, Featureform has built a product called Embeddinghub, which is a vector database for machine learning embeddings. Embeddings are high-dimensional representations of different kinds of data and their interrelationships, such as user or text embeddings, that quantify the semantic similarity between items. MLflow MLflow is an open-source platform for the machine learning lifecycle that covers experimentation and deployment, and it also includes a central model registry. It has four principal components: Tracking, Projects, Models, and Model Registry. In terms of metadata management, the MLflow Tracking API is used for logging parameters, code, metrics, and model artifacts. Versioning For machine learning systems, versioning is a critical feature. As the pipeline consists of various data sets, labels, experiments, models, and hyperparameters, it is necessary to version control each of these parameters for greater accessibility, reproducibility, and collaboration across teams. Pachyderm Pachyderm provides a data layer for the machine learning lifecycle. It offers a suite of services for data versioning that are organized by data repository, commit, branch, file, and provenance. Data provenance captures the unique relationships between the various artifacts, like commits, branches, and repositories. DVC DVC, or Data Version Control, is an open-source version control system for machine learning projects. It includes version control for machine learning data sets, models, and any intermediate files. It also provides code and data provenance to allow for end-to-end tracking of the evolution of each machine learning model, which promotes better reproducibility and usage during the experimentation phase. Experiment Tracking A typical machine learning system may only be deployed after hundreds of experiments. To optimize the model performance, data scientists perform numerous experiments to identify the most appropriate set of data and model parameters for the success criteria. Managing these experiments is paramount for staying on top of the data science modeling efforts of individual practitioners, as well as the entire data science team. Comet Comet is a machine learning platform for managing and optimizing the entire machine learning lifecycle, from experiment tracking to model monitoring. Comet streamlines the experimentation workflow for data scientists and enables clear tracking and visualization of the results of each experiment. It also allows side-by-side comparisons of experiments so users can easily see how model performance is affected. Weights & Biases Weights & Biases is another popular machine learning platform that provides a host of services, including [experiment tracking](https://wandb.ai/site/experiment-tracking). It facilitates tracking and visualization of every experiment, allows rerunning previous model checkpoints, and can monitor CPU and GPU usage in real time. Model Deployment Once a machine learning model is built and tests have found it to be robust and accurate enough to go to production, the model is deployed. This is an extremely important aspect of the machine learning lifecycle, and if not managed well, it can lead to errors and poor performance in production. AI models are increasingly being deployed across a range of platforms, from on-premises servers to the cloud to edge devices. Balancing the trade-offs for each kind of deployment and scaling the service up or down during critical periods are very difficult tasks to achieve manually. A number of platforms provide model deployment capabilities that automate the entire process of taking a model to production. Seldon Seldon is a model deployment software that helps enterprises manage, serve, and scale machine learning models in any language or framework on Kubernetes. It’s focused on expediting the process to take a model from proof of concept to production, and it’s compatible with a variety of cloud providers. Kubeflow Kubeflow is an open-source system for productionizing models on the Kubernetes platform. It simplifies machine learning workflows on Kubernetes and provides greater portability and scalability. It can run on any hardware and infrastructure on which Kubernetes is running, and it is a very popular choice for machine learning engineers when deploying models. Monitoring Once a model is in production, it is essential to monitor its performance and log any errors or issues that may have caused the model to break in production. Monitoring solutions enable setting thresholds as indicators for robust model performance and are critical in solving for known issues, like data drift. These tools can also monitor the model predictions for bias and explainability. Fiddler Fiddler is a machine learning model performance monitoring software. To ensure expected model performance, it monitors data drift, data integrity, and anomalies in the data. Additionally, it provides model explainability solutions that help identify, troubleshoot, and understand underlying problems and causes of poor performance. Evidently Evidently is an open-source machine learning model monitoring solution. It measures model health, data drift, target drift, data integrity, and feature correlations to provide a holistic view of model performance. Conclusion MLOps is a growing field that focuses on organizing and accelerating the entire machine learning lifecycle through best practices, tools, and frameworks borrowed from the DevOps philosophy of software development lifecycle management. With machine learning, the need for tooling is much greater, as machine learning is built on foundational blocks of data and models, as well as code. To bring reliability, maturity, and scale to machine learning processes, a diverse set of MLOps tools are being increasingly used. These tools are developed for optimizing the nuts and bolts of machine learning operations, including metadata management, versioning, model building and experiment tracking, model deployment, and monitoring in production. Over the past decade, the field of AI and machine learning has grown rapidly, with organizations embracing AI and recognizing its critical importance for transforming their business. The field of MLOps is still young, but the creation and adoption of tools will further empower organizations in their journey of AI transformation and value creation. Related Blogs
Comments
|
Archives
March 2024
Categories
All
Copyright © 2024, Sundeep Teki
All rights reserved. No part of these articles may be reproduced, distributed, or transmitted in any form or by any means, including electronic or mechanical methods, without the prior written permission of the author. Disclaimer
This is a personal blog. Any views or opinions represented in this blog are personal and belong solely to the blog owner and do not represent those of people, institutions or organizations that the owner may or may not be associated with in professional or personal capacity, unless explicitly stated. |
 RSS Feed
RSS Feed